很多情况下,需要从不同的数据源中提取数据,并将数据格式进行转换,定义不同的流程,传输到对应的系统中
需求较为简单的情况下,可以通过自己写代码实现,但在数据流比较复杂后,整个流程难以维护,扩展性很差
这时候就需要引入像 NiFi、StreamSets 这类的 DFM(Data Flow Management) 数据流处理平台,这篇文章主要介绍在 NiFi 中定义一个简单的数据流
Demo
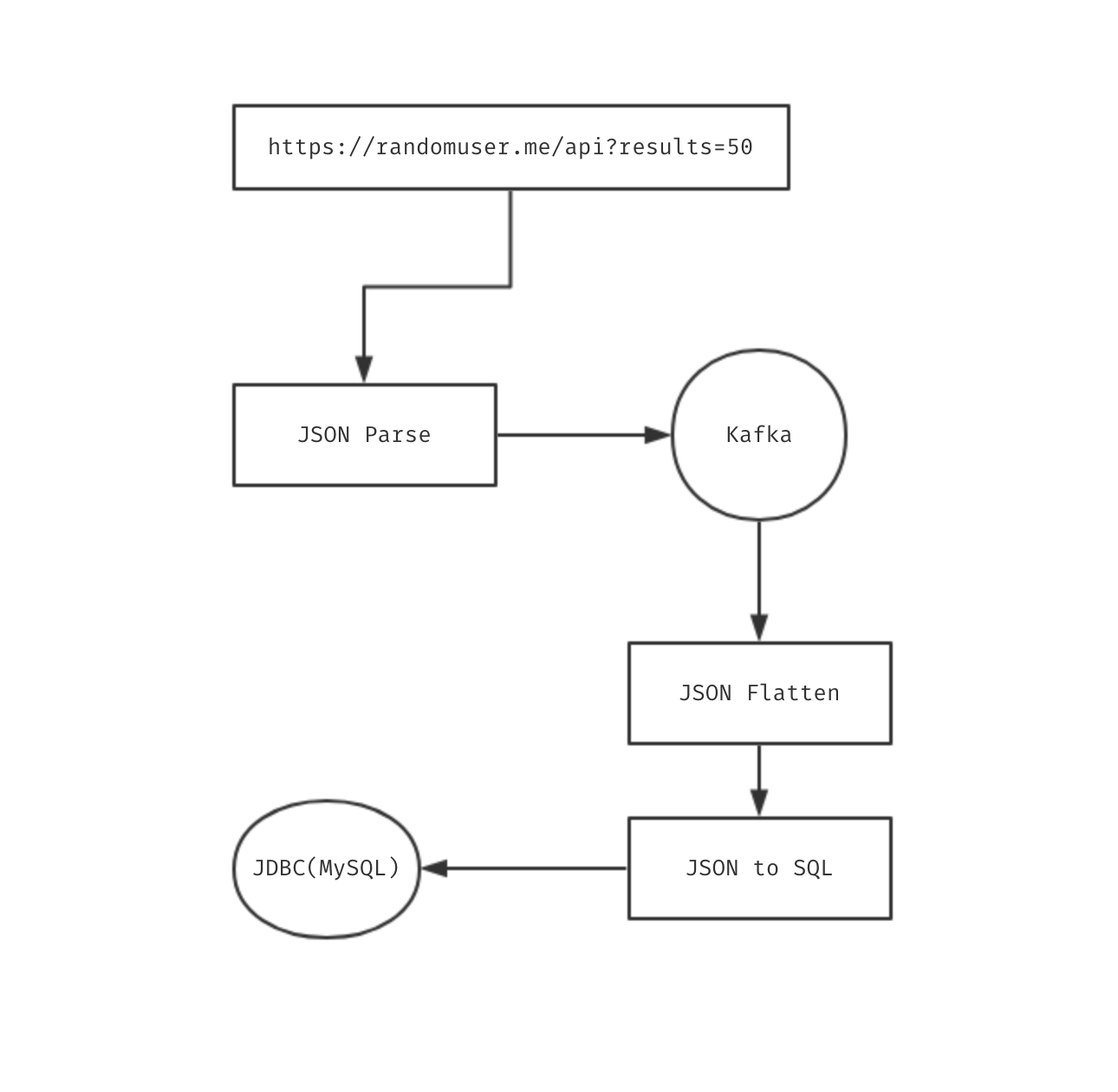
我们需要定义以下数据流,从数据的生产到消费,主要有以下步骤
生产
- 通过 randomuser api 获取用户数据
- 处理返回的数据
- 将处理过后的数据发送给 kafka
消费
- 从 kafka 获取用户数据
- 展开 json 数据
{"login": {"username": "anyisalin"}} -> {"login.username": "anyisalin"} - 将展开后的 json 数据转化为 SQL 语句
- 执行 SQL
NiFi
安装
NiFi 安装很简单,在 Linux 系统上安装好 JDK 环境,https://nifi.apache.org/download.html 下载并解压对应版本的二进制安装包,执行以下命令即可
cd nifi-<VERSION> |
等待启动完成后访问对应 IP 的 8080 端口即可
架构
Flowfile 是NiFi及其基于流的设计的核心,流文件是一个数据记录,它由指向其内容的指针和属性组成,并与相关事件进行关联
NiFi 架构如下,由几个组件组成
Web Server:NiFi 的 http 接口
Flow Controller:对 Processor 的流程控制、资源调度
FlowFile Repository:存储 Flowfile 元数据(attribute、指向内容的指针)
Content Repository:存储 Flowfile 内容
Provenance Repository:存储 Flowfile 运行时状态

创建数据流
invoke http
首选我们要定义调用 randomuser api 获取用户数据,NiFi 中通过 Invoke HTTP 这个 Processor 发起 HTTP 请求
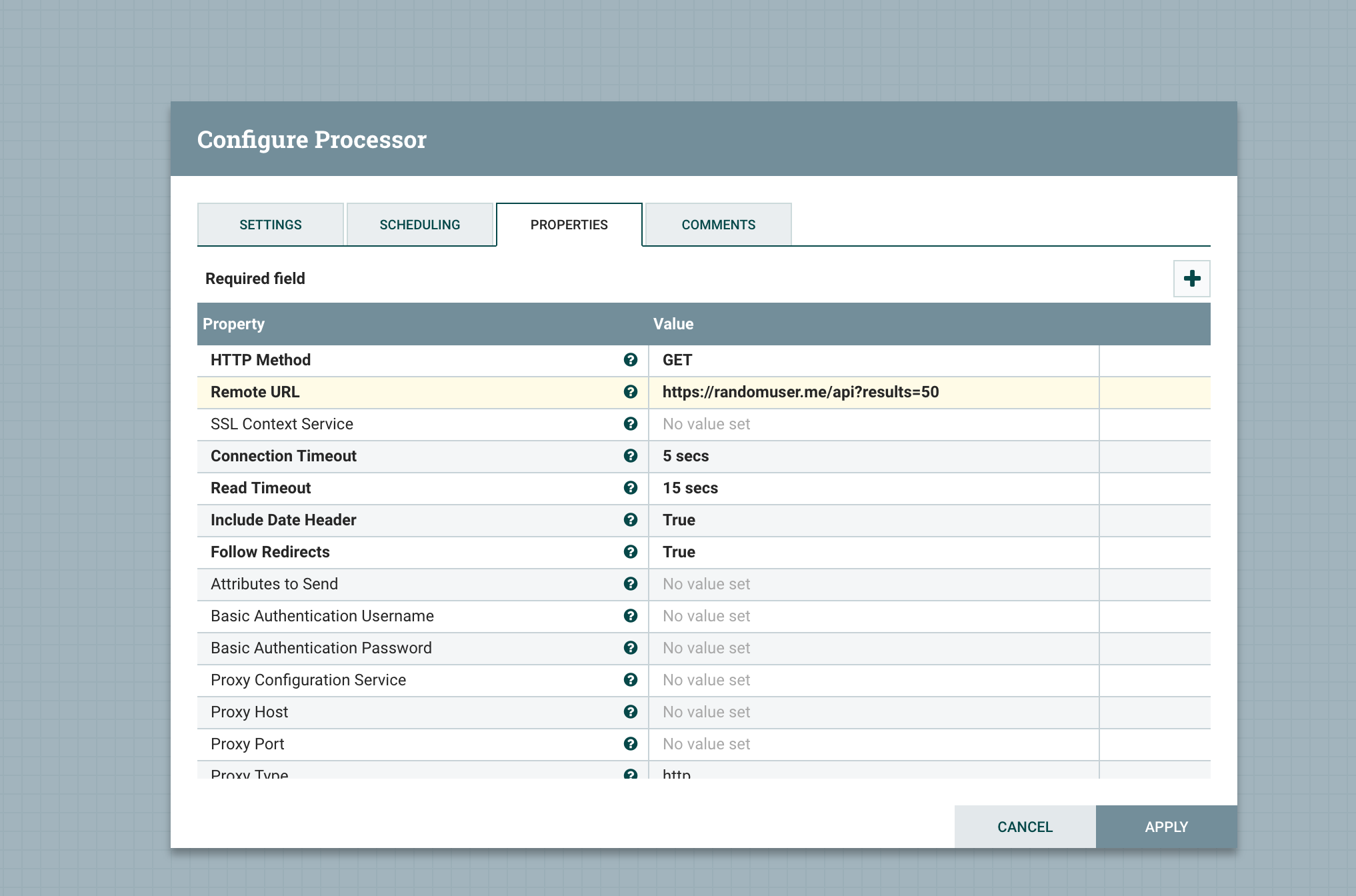
这个 HTTP Endpoint 返回的资源格式如下 https://randomuser.me/api?results=50
{ |
SplitJson
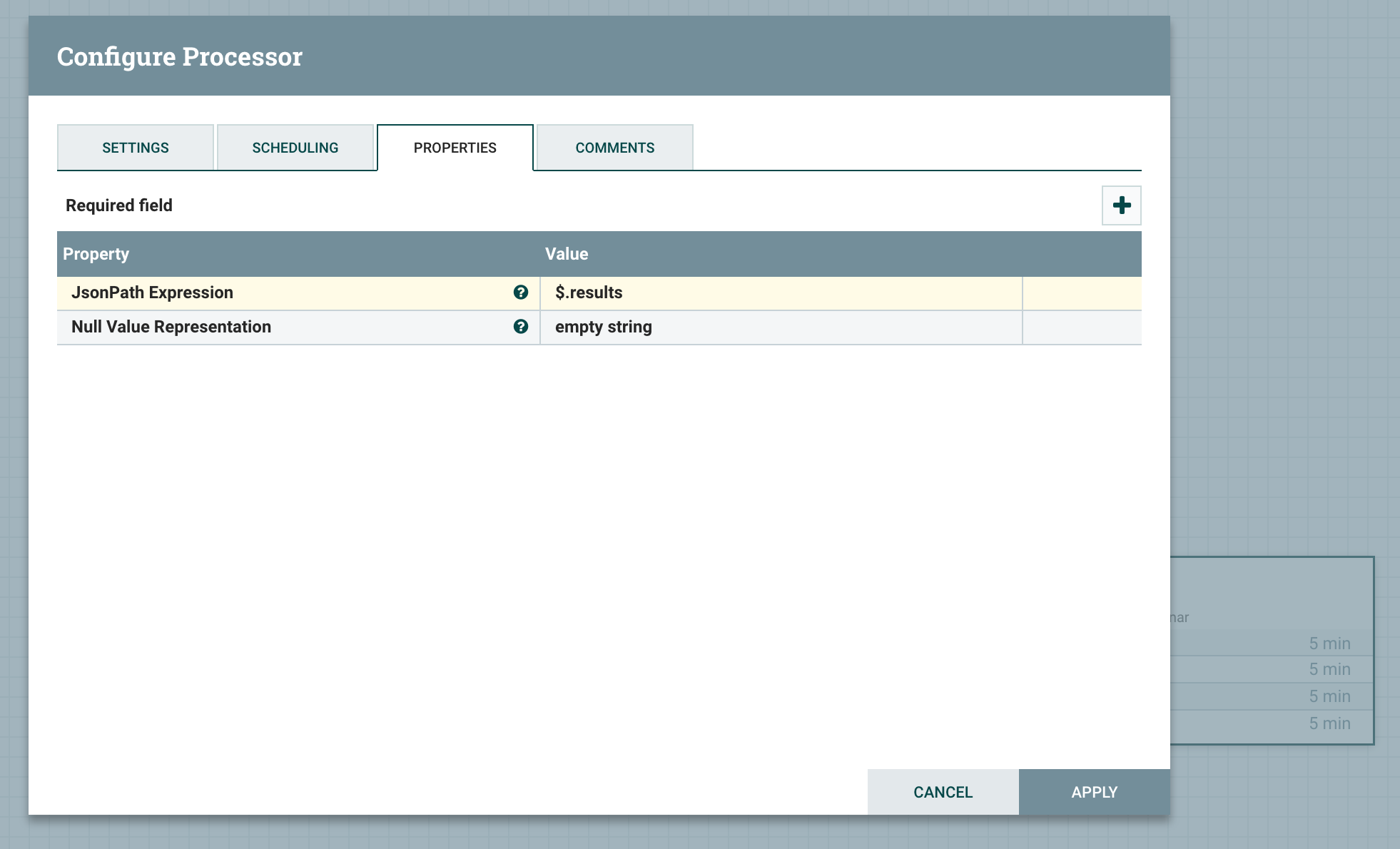
我们只需要 results 里面的数据,所以需要进行切分
NiFi 中通过 SplitJson 来切分 JSON 数据
定义完这两个 Processor ,可以先测试一下
将两个 Processer 连接起来
这里的 Relationships 是根据 Processor 中 Flowfile 的状态,需要定义对应状态下的 Flowfile 应该路由到哪一个 Processor
我们这里定义 Relationships,Response 数据流路由到 SplitJson
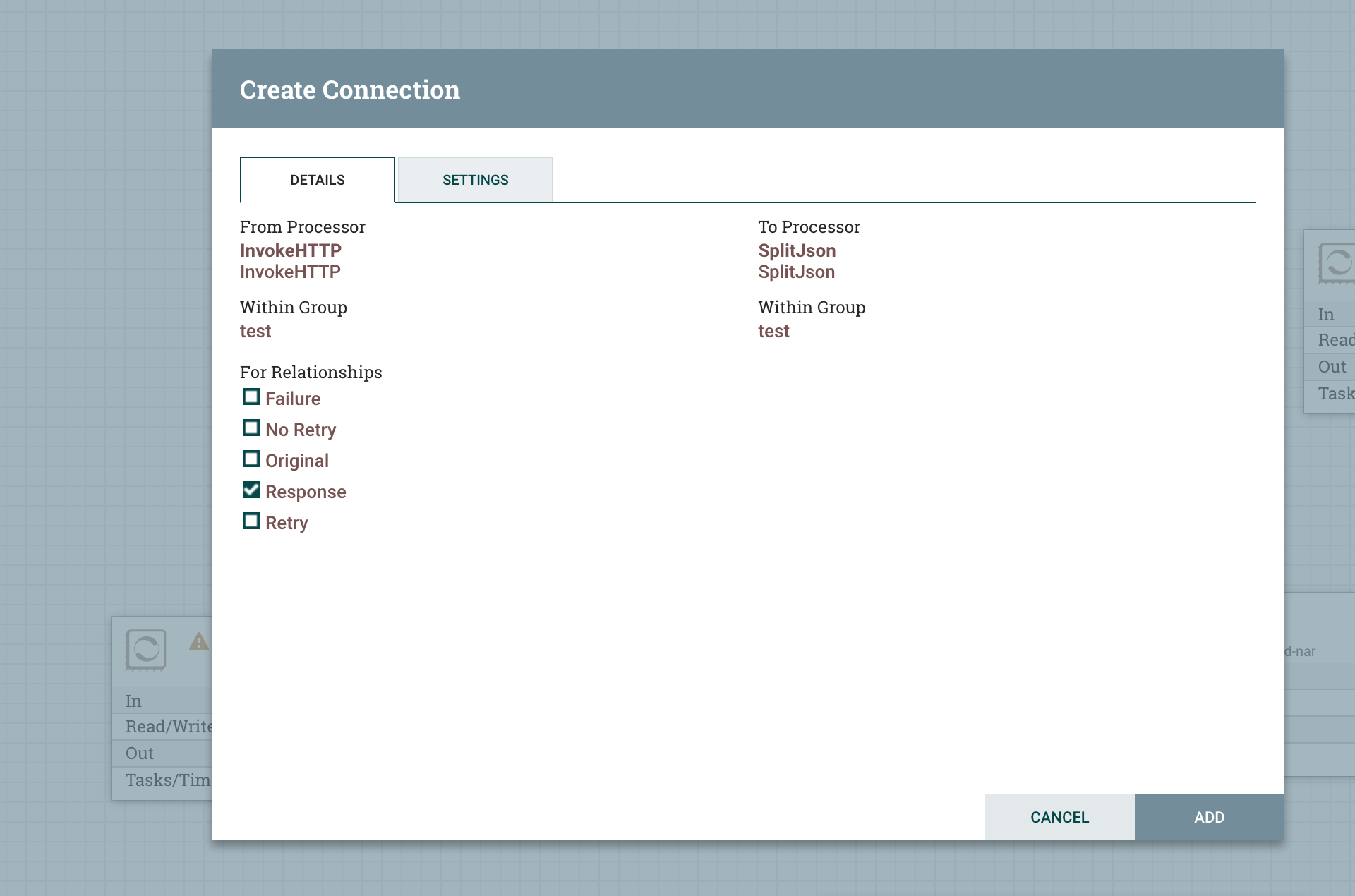
但是在 NiFi 中,所有的 Relationships 都得定义,所以对应的 Failure、No Retry、Original、Retry 也得路由到对应的 Processor,我们这里使用 DebugFlow 来接收这些错误的数据
Automatically Terminate Relationships 指的是数据流路由到这个 Processor 后,特定状态下会被删除,一般在 Endpoint Processor 配置,因为数据流不需要再被继续路由了
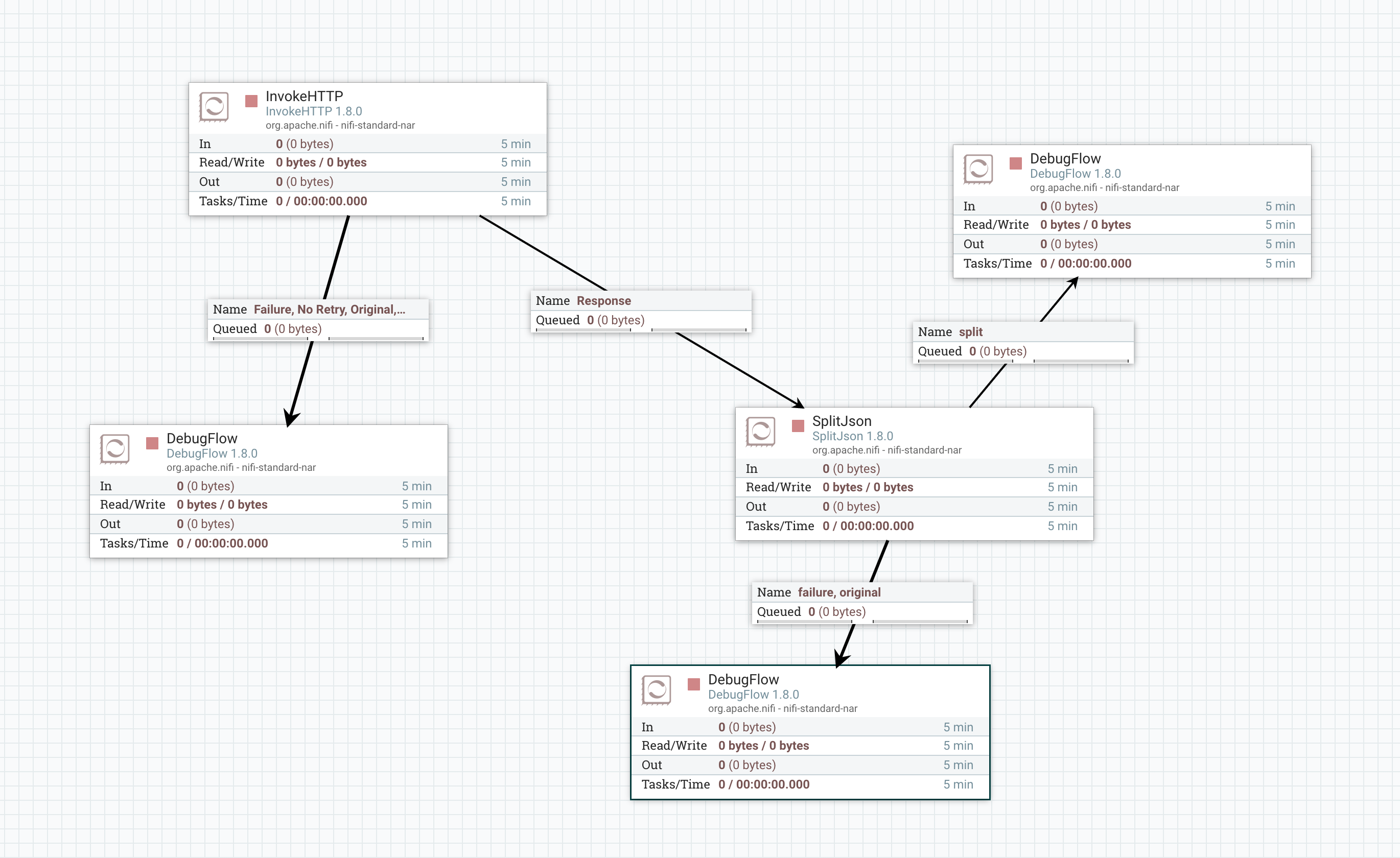
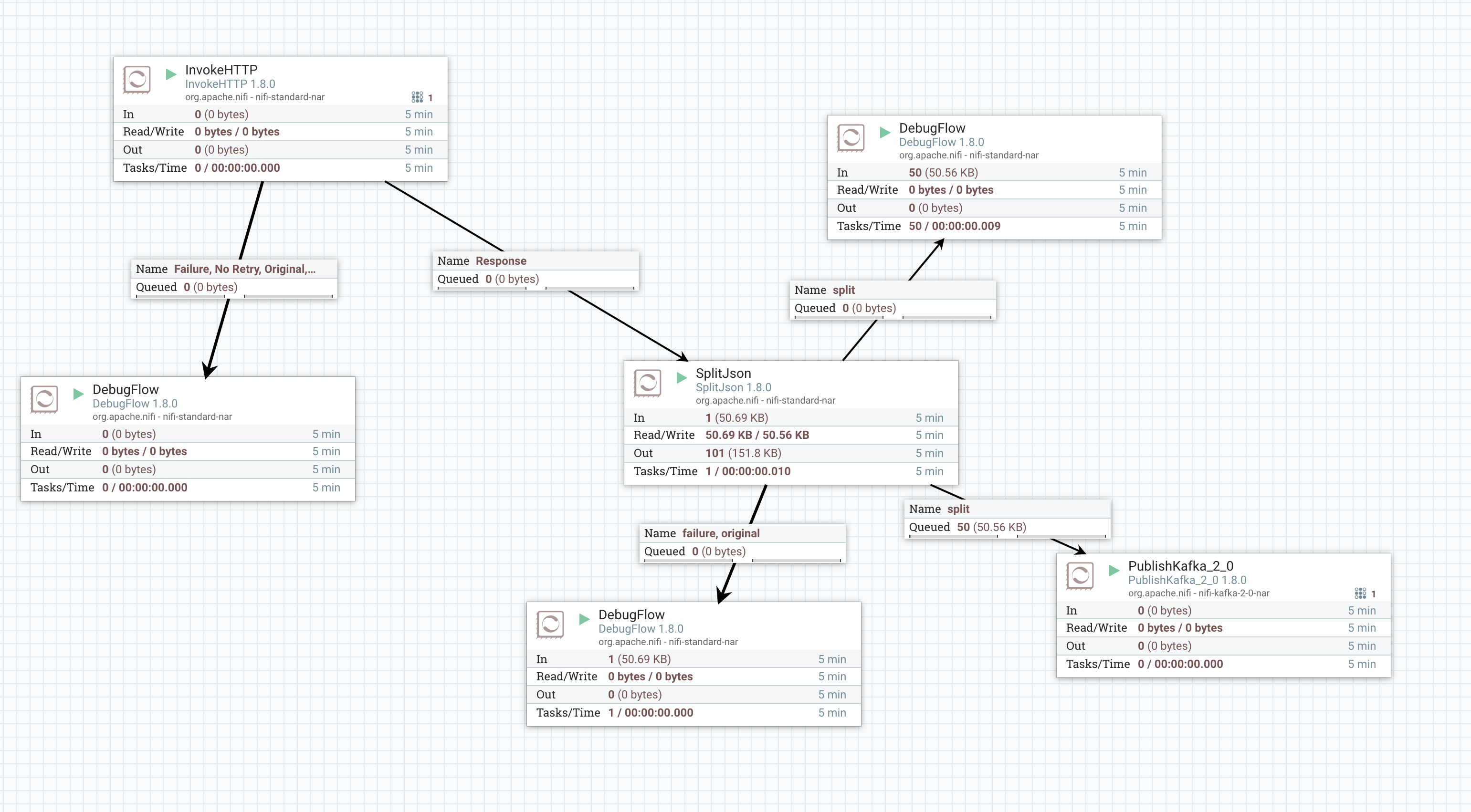
最后我们这个简单的数据流如下
启动数据流之后,通过 NiFi Data Provenance 可以看到数据流的状态
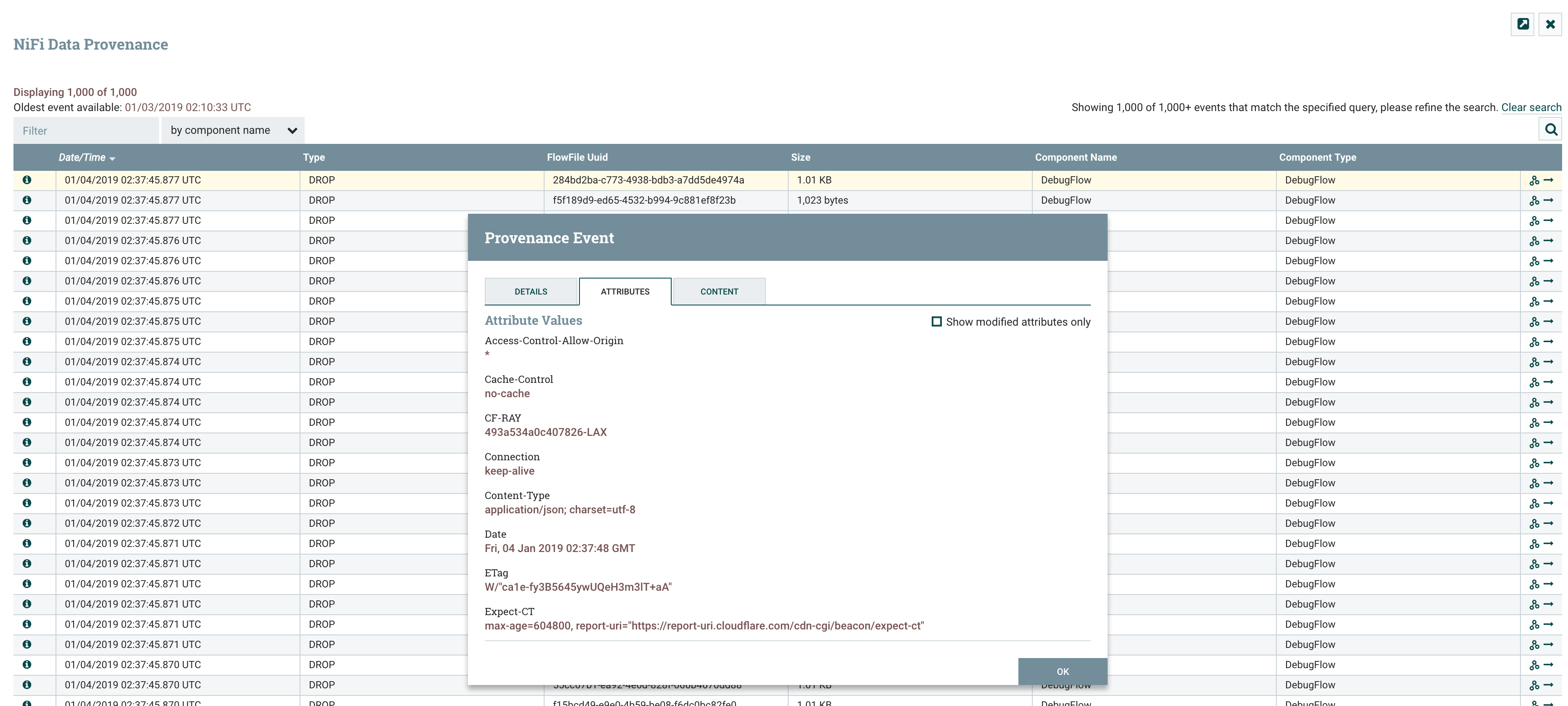
可以看到 JSON 数据已经被切分了

kafka producer
完成 JSON 数据的切分过后就可以将数据存储到 Kafka 中了
我们需要创建 PublishKafka Processor,由于 Kafka 不同版本的 API 不兼容,所以 NiFi 提供了多个版本的 Processor
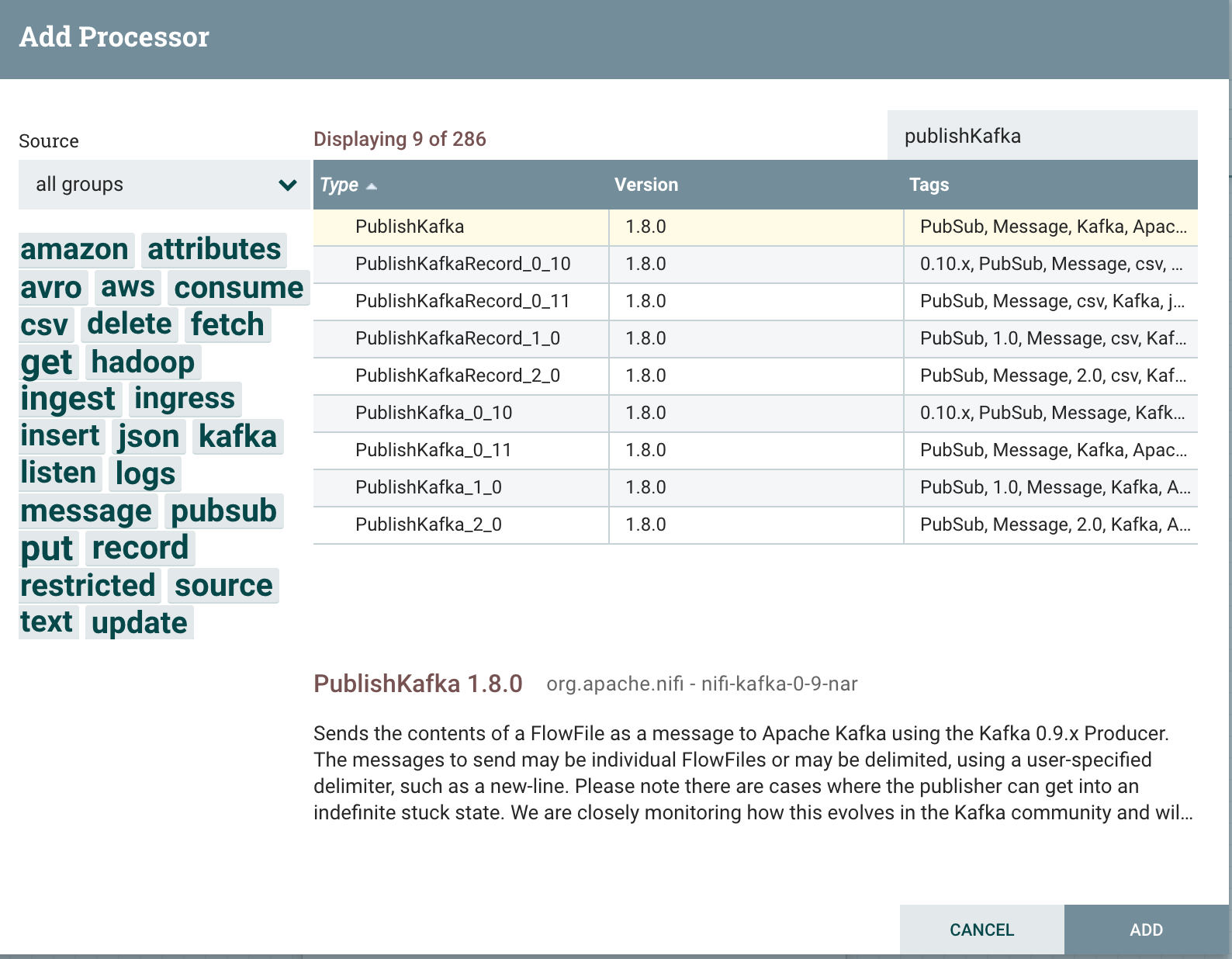
我们这里使用的是 2.1.2 版本的 Kafka,所以用 PublishKafka_2_0 即可
配置好 Kafka 的连接参数
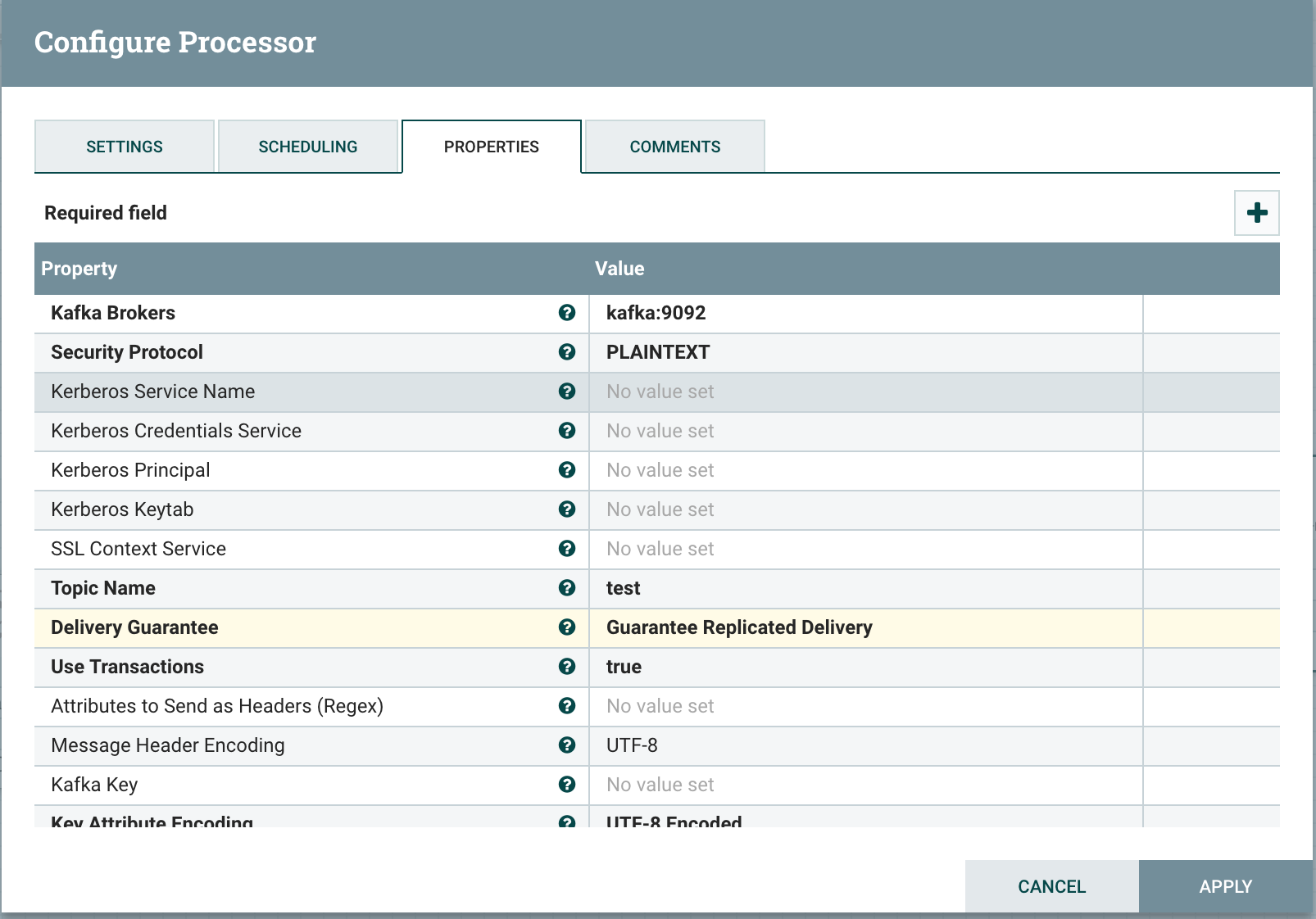
由于 Kafka 在这个数据流中是 Endpoint Processor,数据流不需要再被路由了,所以 Automatically Terminate Relationships 都勾选上
将 SplitJson 与 PublishKafka 连接,整个数据流就构建好了
kafka consumer 测试
能够从 kafka 消费数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning |
ConsumerKafka
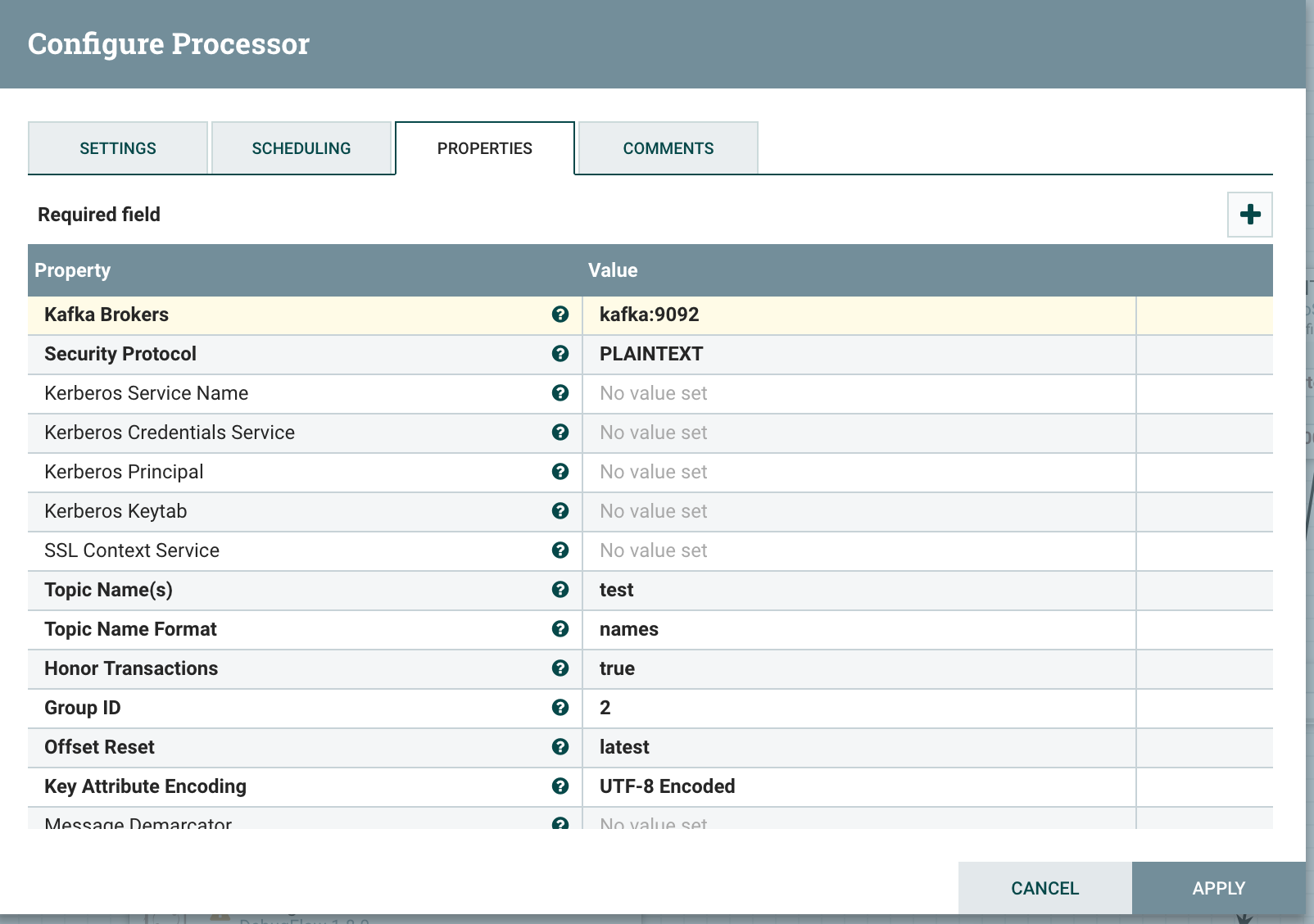
创建 ConsumerKafka Processor
配置 Kafka 连接参数
FlattenJson
创建 FlattenJson Processor
配置 Separator 为下划线 _
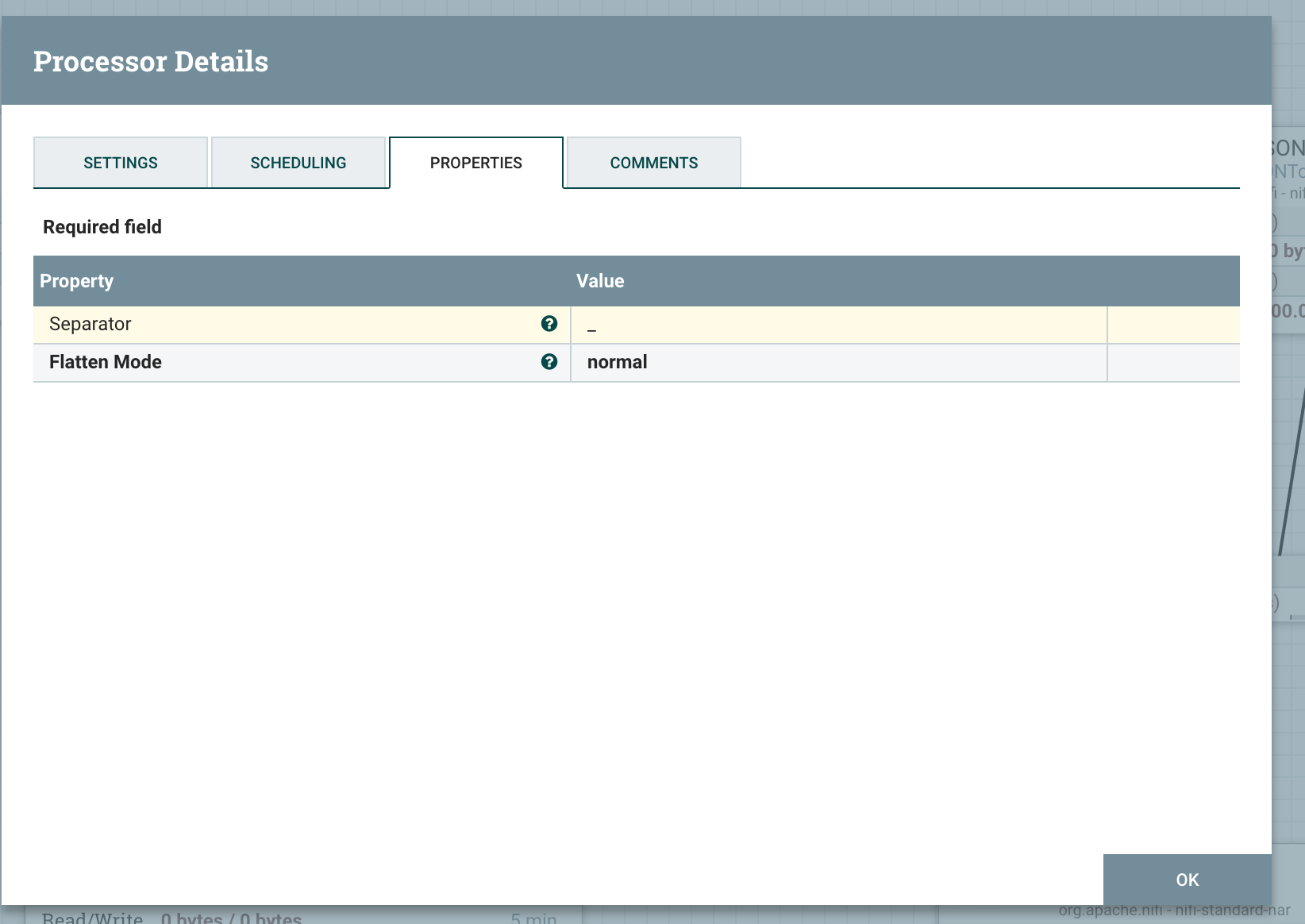
展开的格式如下
{'gender': 'male', |
连接 FlattenJson 和 ConsumerKafka
ConvertJSONToSQL
首先在 MySQL 中创建库和表
表结构如下
create table users ( |
创建 ConvertJSONToSQL Processor
在 NiFi 中创建并配置 MySQL service,需要指定 Connector Driver 的路径和类名(这里使用的是 MariaDB),并填写 用户名、连接地址等参数
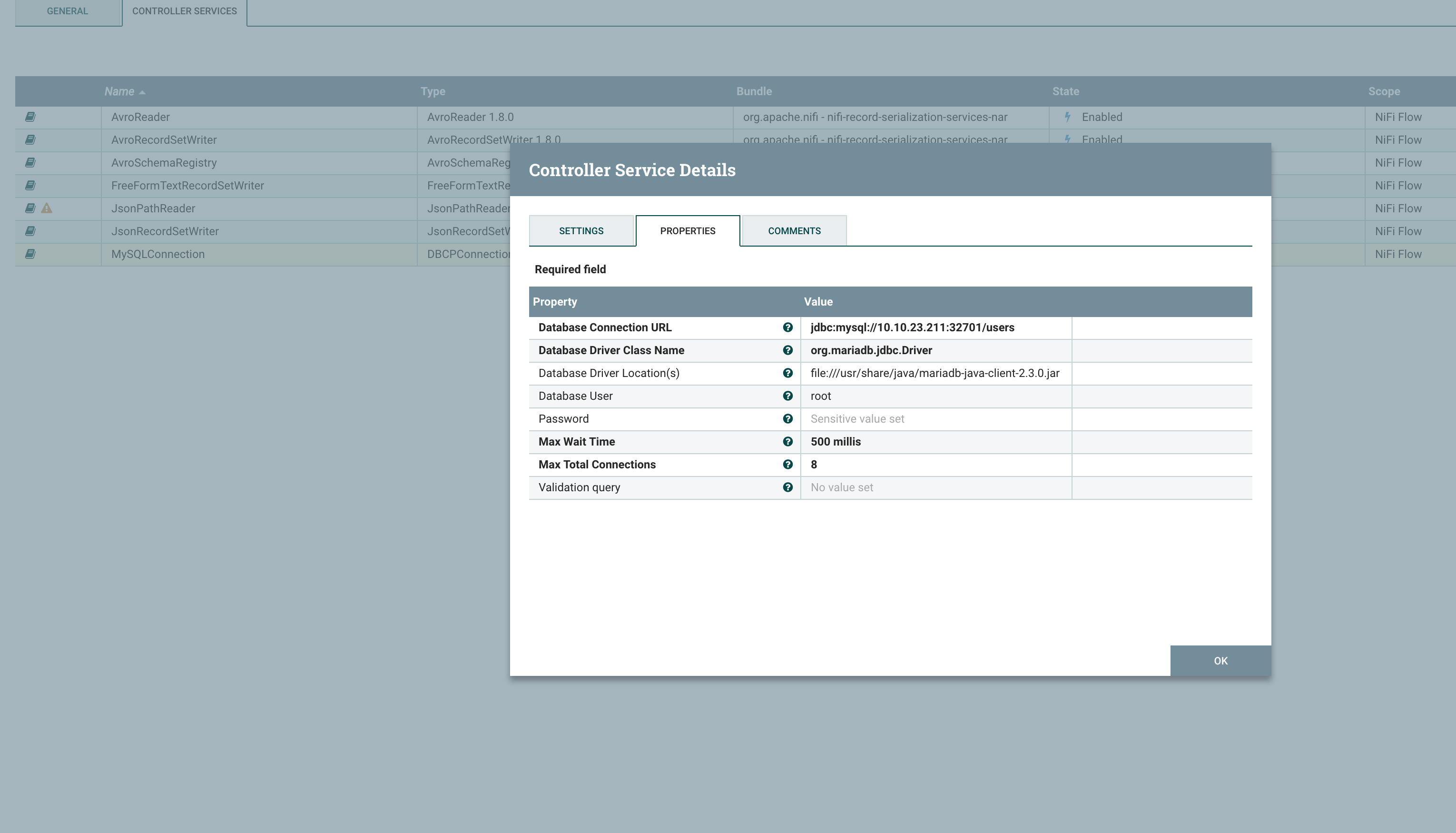
创建好 MySQL Service 后在 ConvertJSONToSQL 中配置对应的参数
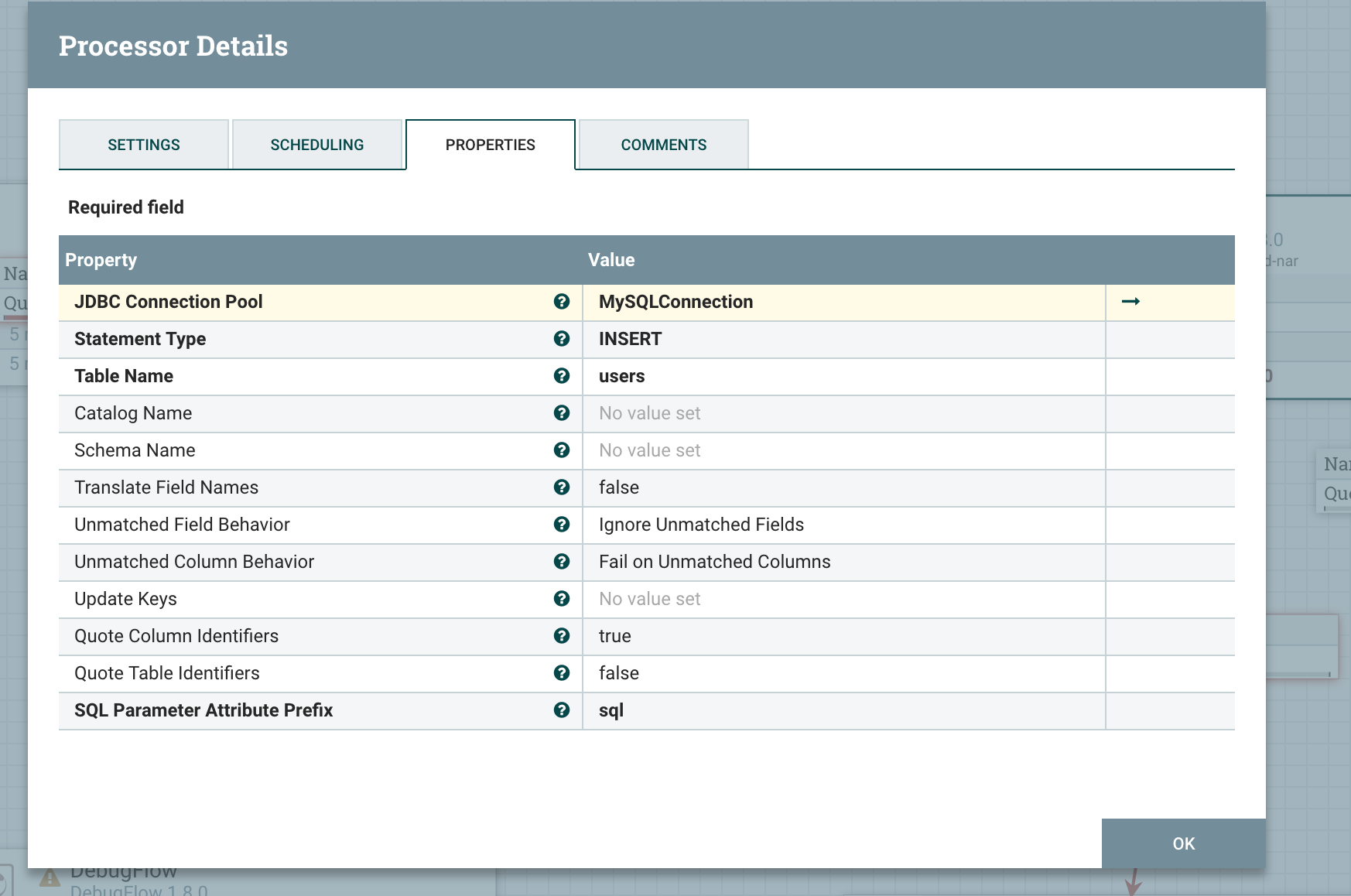
连接 ConvertJSONToSQL 和 FlattenJson
ExecuteSQL
创建 ExecuteSQL Processor
配置对应的数据库连接池,这里可以复用上一步创建的 MySQLConnection Service
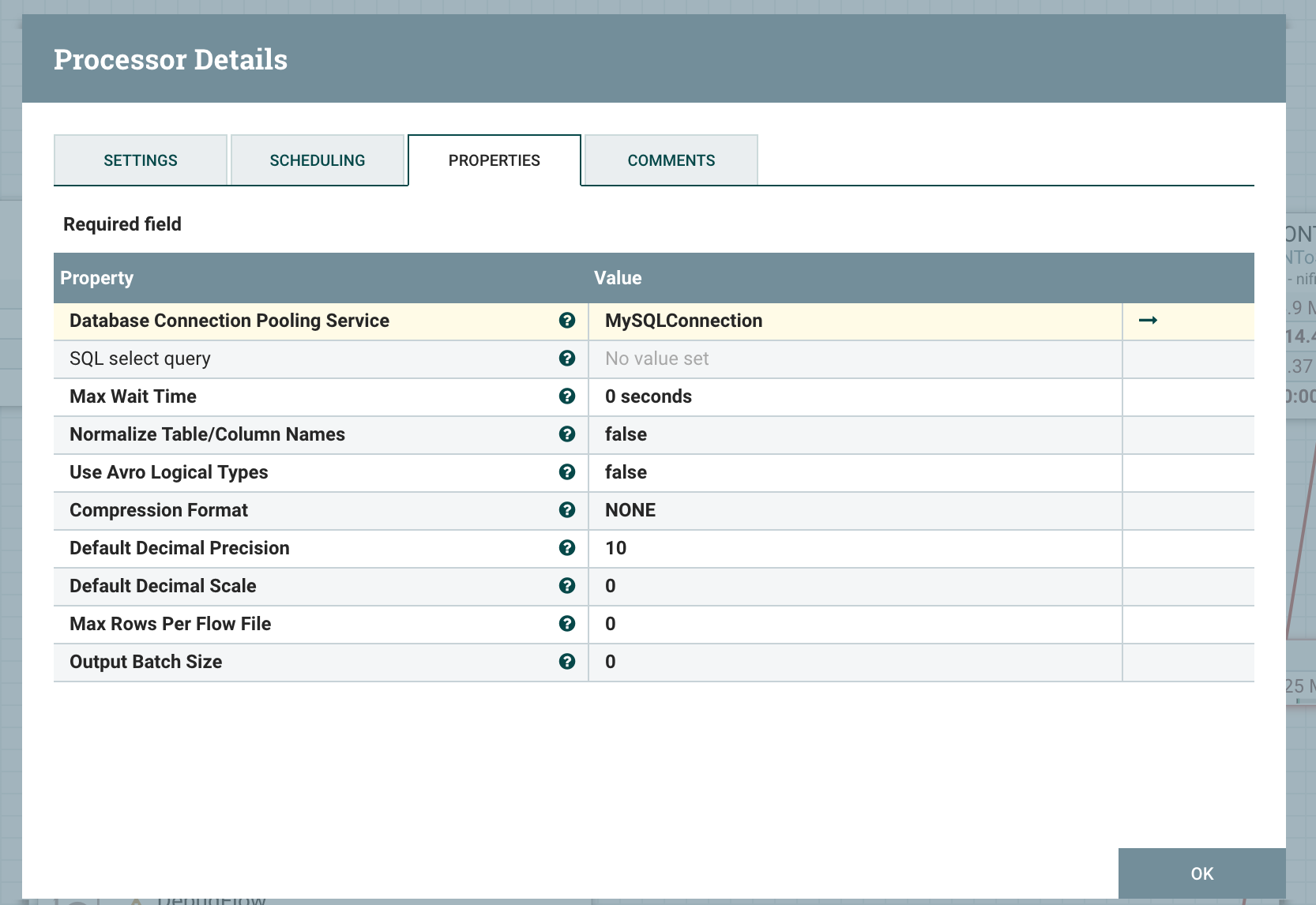
连接 ExecuteSQL 和 ConvertJSONToSQL
测试
最后我们的数据流如下
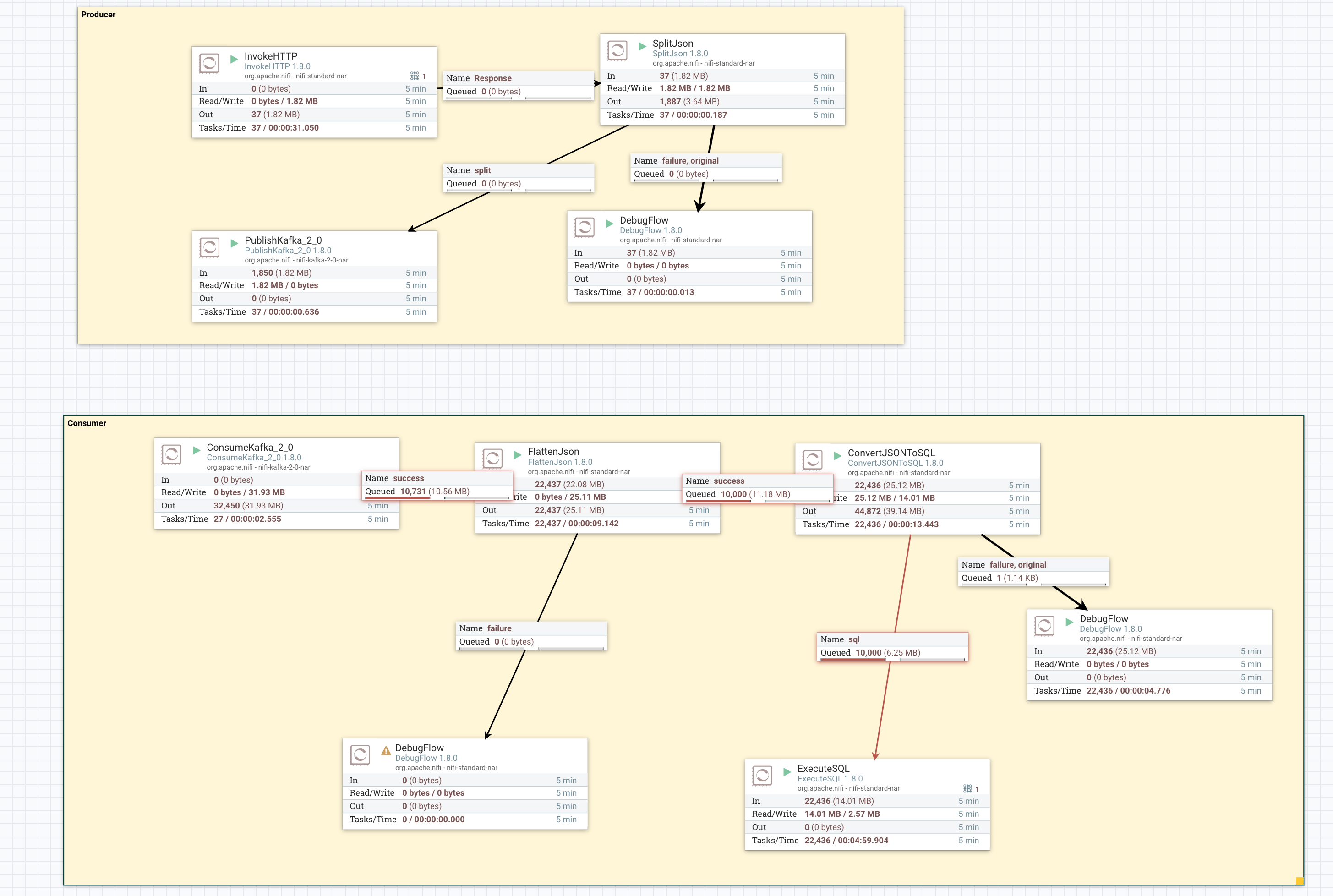
查询数据库,不断的有数据插入
mysql> select count(login_username) from users; |
限流
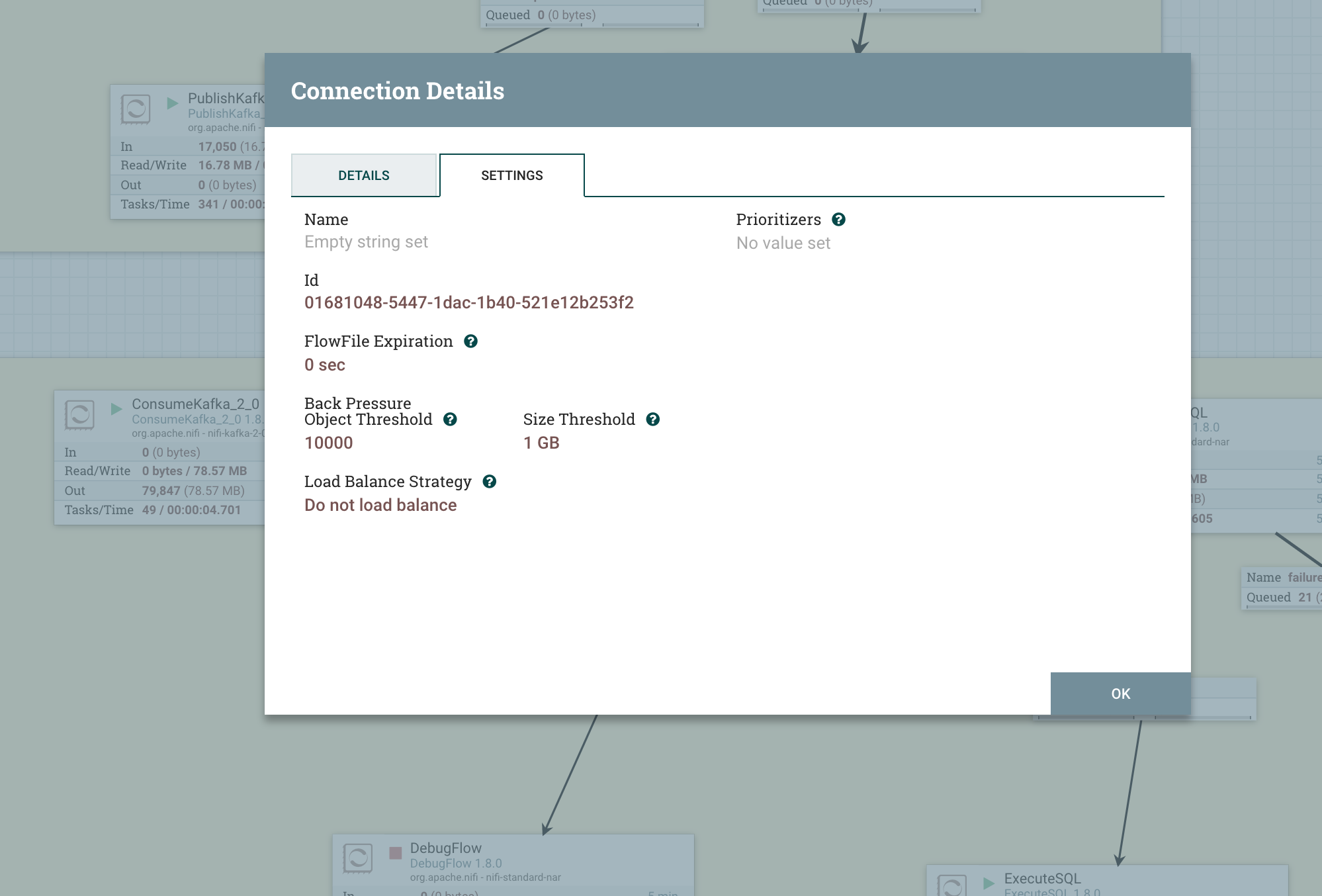
当 上游数据生产的过快,无法及时消费,就需要限流,限制上游的连接数,防止数据过载对整个数据流的影响
NiFi 可以对每一个连接的队列设置阈值
默认是 1000 个 flowfile 或者 1G 大小
总结
了解了 Processor 和 Flowfile 的状态和流程,在 NiFi 中定义 数据流还是很容易的,NiFi 自带的 Processor 种类也非常丰富,也支持自己写对应的 Processor
在 NiFi 中定义了数据流之后,就可以很清晰的看到流式数据的路由,状态,也很容易地对现有的数据流进行扩展