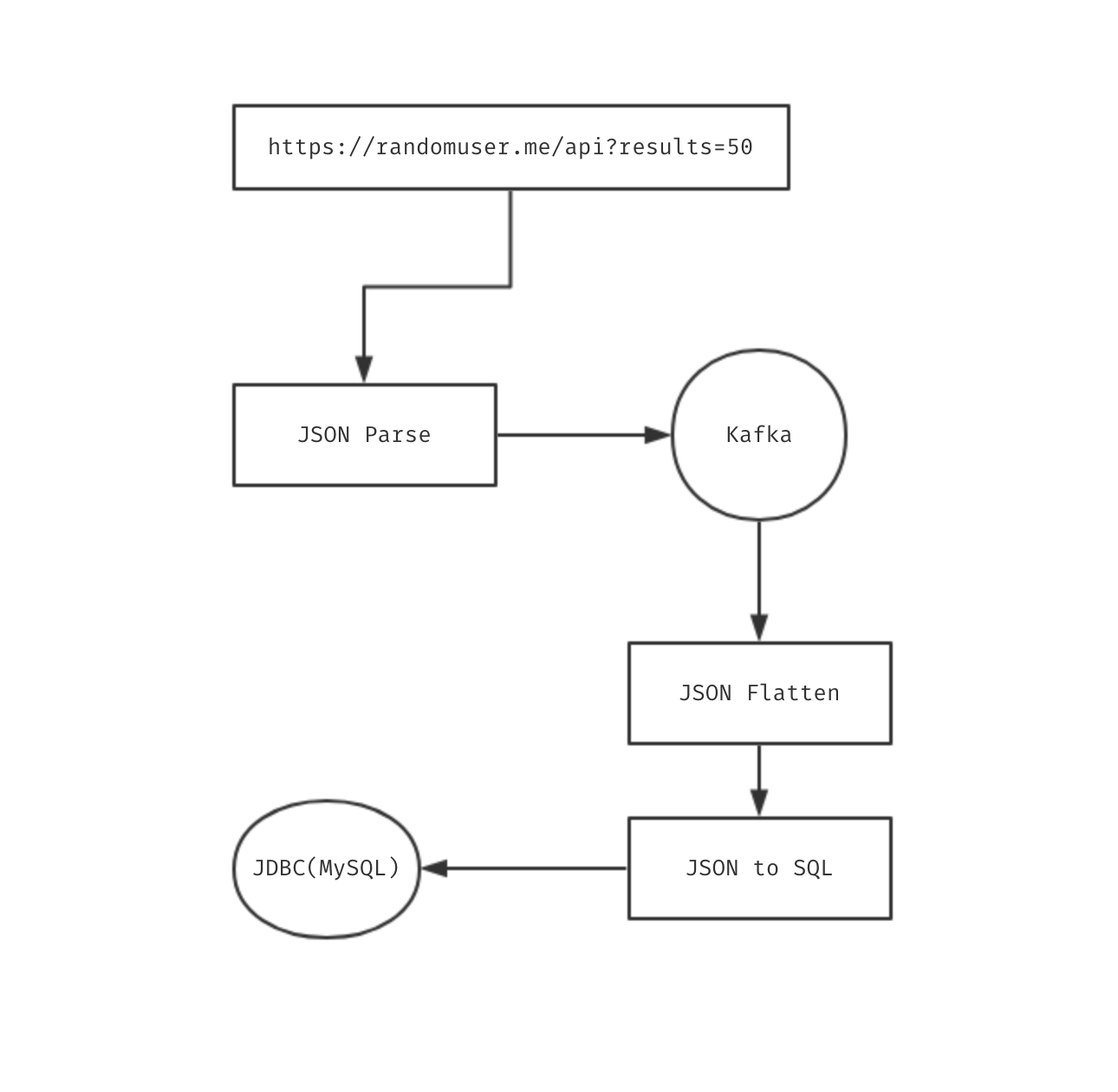
听说最近 kubesphere 3.0 要发布了,周末无聊,遂研究一下。
笔者已经存在一个基于 kubeadm 部署,5 节点的 k8s 集群,架构如下
- Kubernetes 版本 1.18.3
- 操作系统 Ubuntu 18.04.2 LTS 内核 5.4.0-37-generic
- 网络: cilium
- 存储: rook + ceph
- 使用 metallb 作为 LoadBalancer,nginx-ingress 作为 IngressController
- kube-prometheus + Thanos
看 Requirements 是不支持笔者的 k8s 版本的,但是按理来说区别不大,所以就有了以下踩坑记录。