Introduction
笔者最近有个需求,需要在没有文档的前提下梳理清公有云上数百台虚拟机之间的依赖关系,遂花了点时间研究了一下。
The value of the idea ?
由于一些历史遗留问题,我们没有办法知道一些资源 (多台云主机) 之间的关系,它们是否是孤立的,还是会和哪些系统进行交互,是否还有必要存在。
对于微服务架构来说很容易做到这种链路状态监控,而对于传统的基础设施层面,这类信息一般都是以文档或者CMDB 以静态方式呈现,而静态的信息又不一定完全准确,维护这些关系的工作也非常的繁琐,如果能够在基础设施的层面建立起类似微服务的链路依赖关系对于运维人员是很有价值的。
Prototype Design
Gets the network TCP/IP connection
如果两台机器有关联,大部分情况下都会基于 TCP/IP 协议进行网络通信,所以能拿到所有虚拟机的网络链接情况并基于这些数据进行分析应该就能得出所有虚拟机之间的依赖。
大家都知道 Linux 上有 netstat -tunlpa 命令可以列出系统目前的所有 TCP/UDP 连接情况
netstat -tunlpa |
基于上面的结果我们可以得出以下拓扑关系
13.20.0.95 -> 13.20.0.28 |
Store data to the graph database
但是上面这种情况比较少见,只是一对一的关系,更多的情况是像下面这样
netstat -tunlpa |
这种情况我们就难以维护拓扑关系了,我们需要借助专门设计用于存储拓扑关系的图数据库,我们只需要把每个节点的链接信息在图数据库里关联,这里使用 Neo4j
MERGE (ip1:IP{ |
在图数据库中展现如下
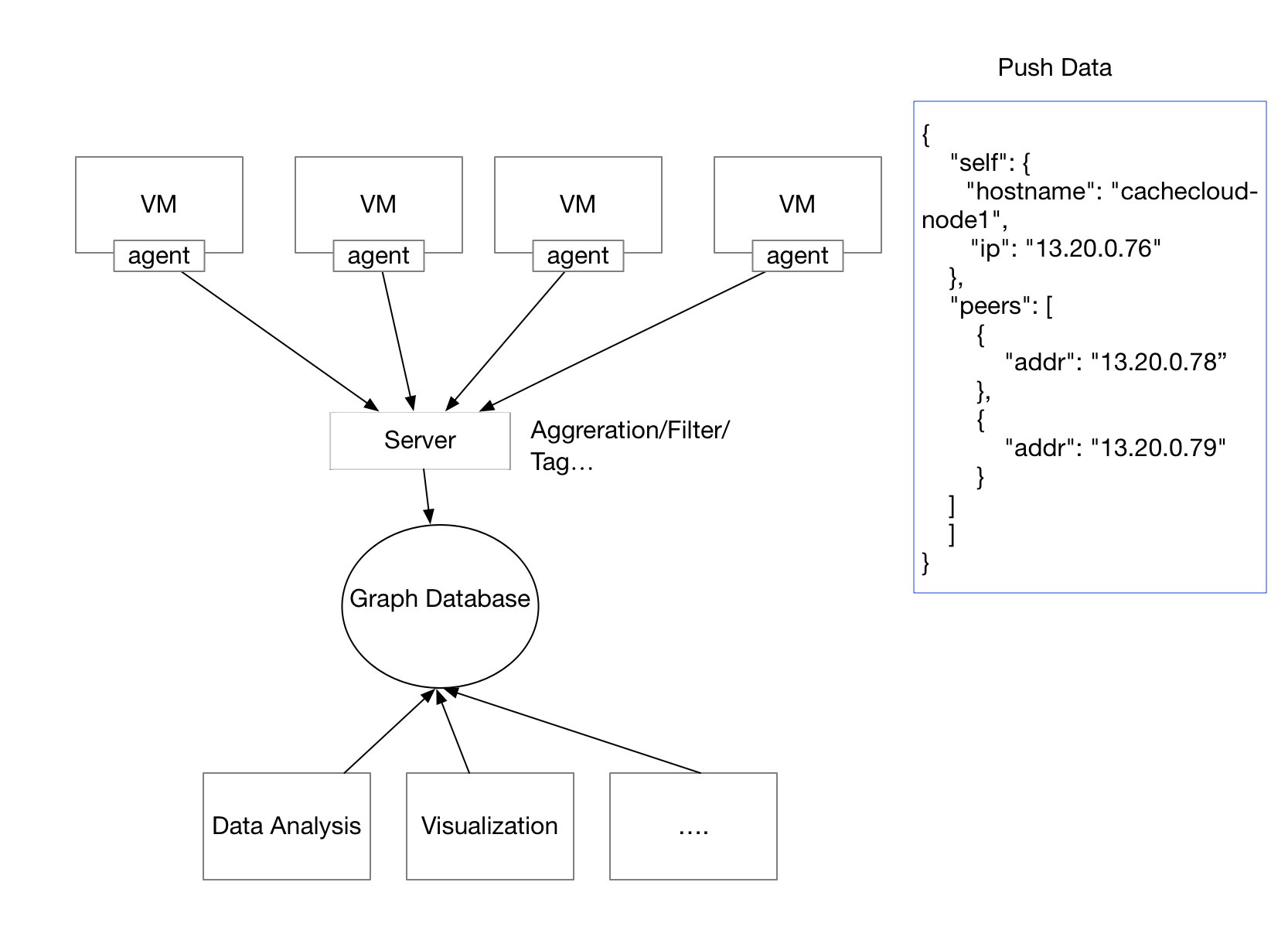
System architecture design
现在我们已经把逻辑都理清了,接下来就要进行软件工程上的设计与实现了
- 在每台虚拟机上部署 Agent 监控网络连接并通过 HTTP 协议上报给服务端
- 服务端对 Agent 传输过来的数据进行 聚合、过滤、打标签
- 存储到图数据库用于数据分析和可视化
最后我们的系统架构图如下
Putting this into practice
Writing Agent
这我们用 Go 语言来编写 Agent,由于 Go 语言的特性,天生适合这种场景
我要先要获取所有的网络连接情况,通过 netstat 这个库我们可以像 Linux 命令 netstat 一样拿到网络连接信息
package main |
然后我们还要拿到当前的主机名和 IP 地址(不考虑多个 IP 地址的情况)
package main |
完整代码放在 https://github.com/AnyISalIn/infra_graph_collector/blob/master/pkg/agent/agent.go
Writing Server
服务端的功能主要是监听一个 HTTP Endpoint,接受 Agent 传递过来的数据,然后构建出对应的 SQL 语句,首先要构建 Agent 自身,然后构建它和 TCP 连接之间的依赖
func buildSelf(host, addr string, c chan string) { |
然后把数据存储到图数据库即可,这里使用 Neo4j
for { |
完整代码放在 https://github.com/AnyISalIn/infra_graph_collector/blob/master/pkg/server/server.go
Testing
笔者通过 Ansible 将 agent 下发到 50 台虚拟机中,最后在图数据库中展现效果如下
这里的 nebula 就是架构中的 Server 节点,所有的虚拟机都会和这台机器通信,所以所有虚拟机都会和这台节点有关联
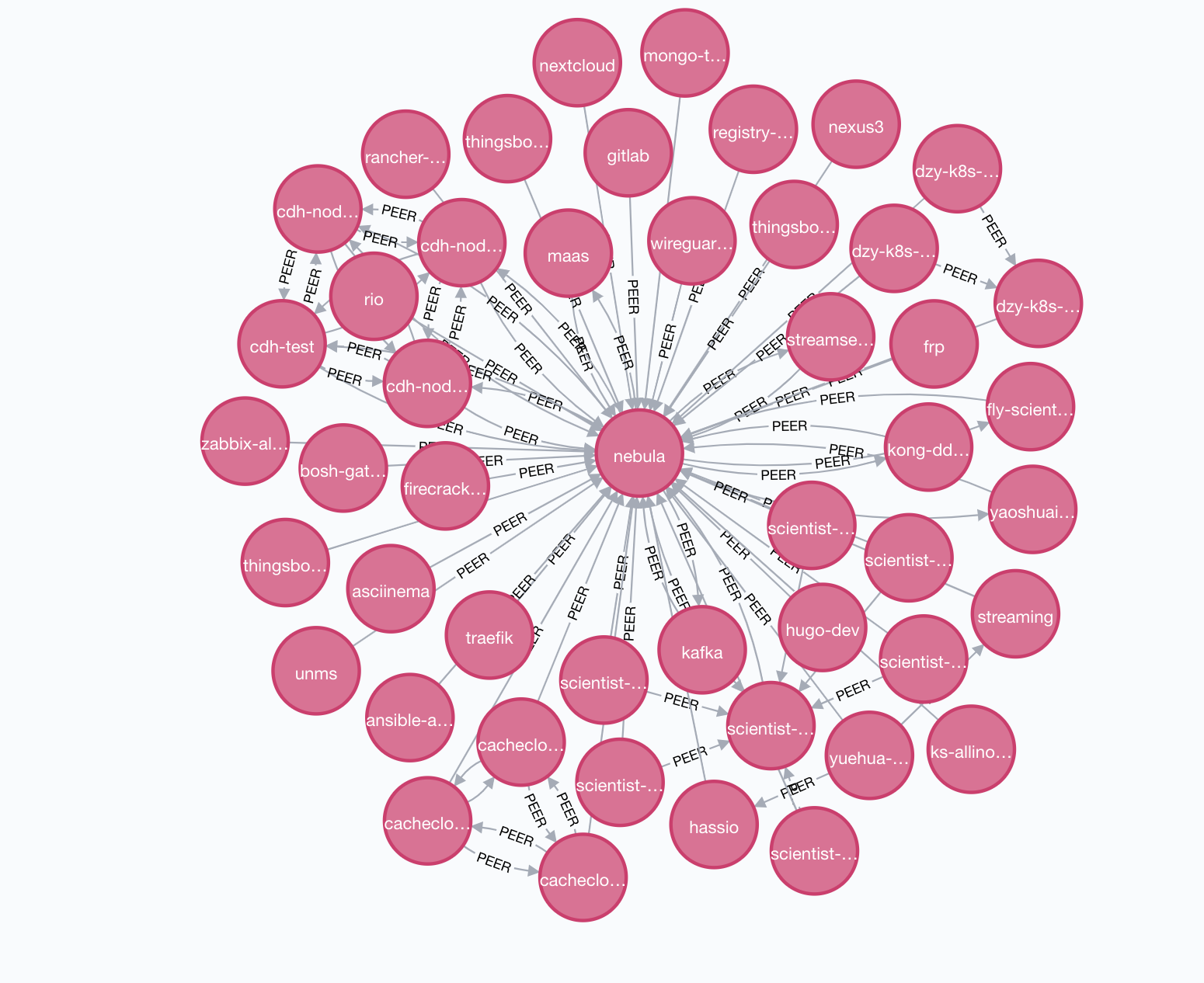
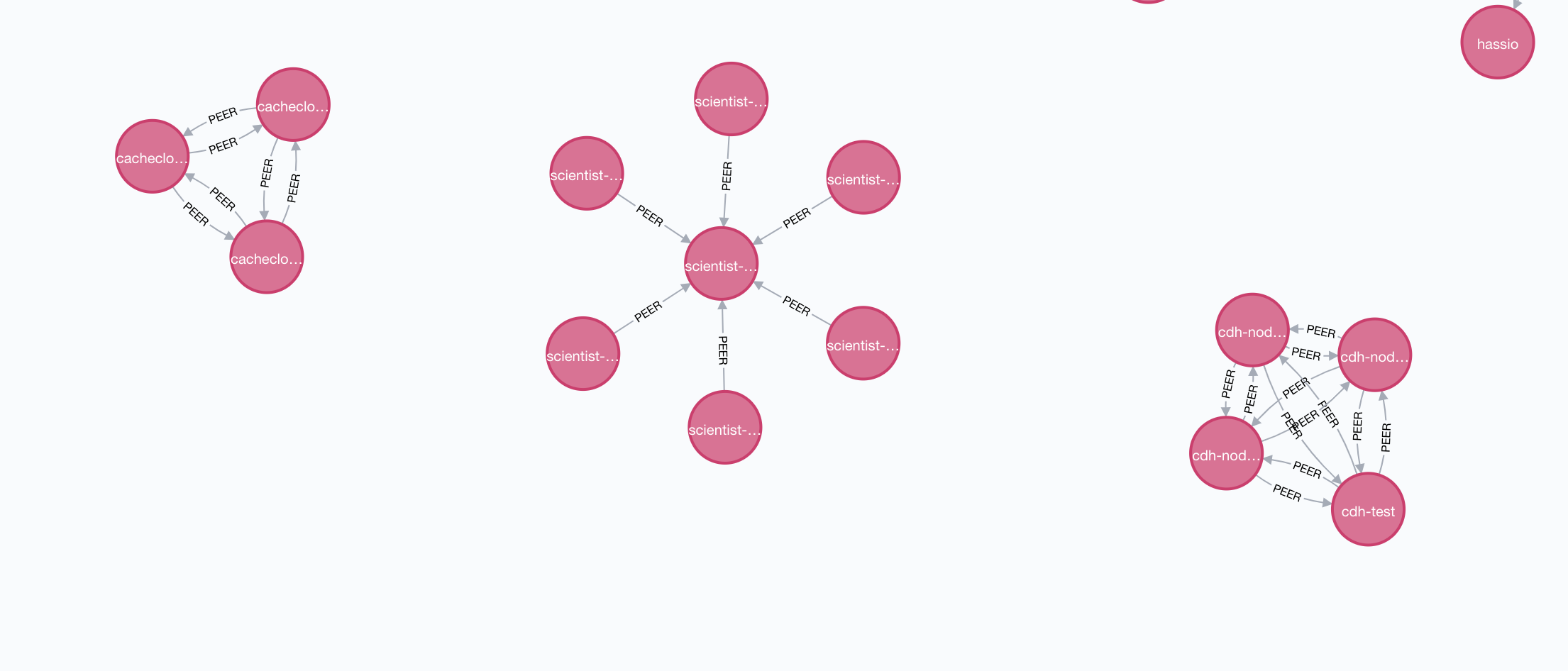
我们隐藏 nebula 节点后可以发现几个集群,左边是 Cachecloud 集群,中间是 Kubernetes 集群,右边是 Hadoop 集群,因为 Kubernetes 集群中所有节点一般只会和 Master 通信,所以会出现这种结构的关系,而 Hadoop 和 Cachecloud 集群每个节点都会相互通信,所以会出现这种互联的结构。
Next Step ?
表面上我们已经完成了节点之间的关系图,其实只算完成了一半,实际上我们只对 IP 之间进行了关联,虚拟机会存在多个 IP 的情况,并且对与 Remote Port 我们也没有进行处理,并且在云上,有很多 PAAS 服务无法运行 Agent,也需要单独做处理,这块还有很多要做的工作。
Server 端目前只存储数据,并没有过滤和打标签,如果根据用户提供的一些数据给每个节点打上业务的标签能够分析出更有价值的关系图。
当然这只是笔者花了几个小时的简单尝试而已,如果要应用到生产还是要做很多改动的。