StreamSets 有三个组件
- StreamSets Edge:主要安装在物联网设备上,采集数据
- StreamSets Data Collector:ETL、dataflow 工具
- StreamSets Control Hub:管理 Data Collector 定义的 pipeline
本文主要介绍通过 StreamSets Data Collector(以下简称 SDC) 定义数据流
Demo
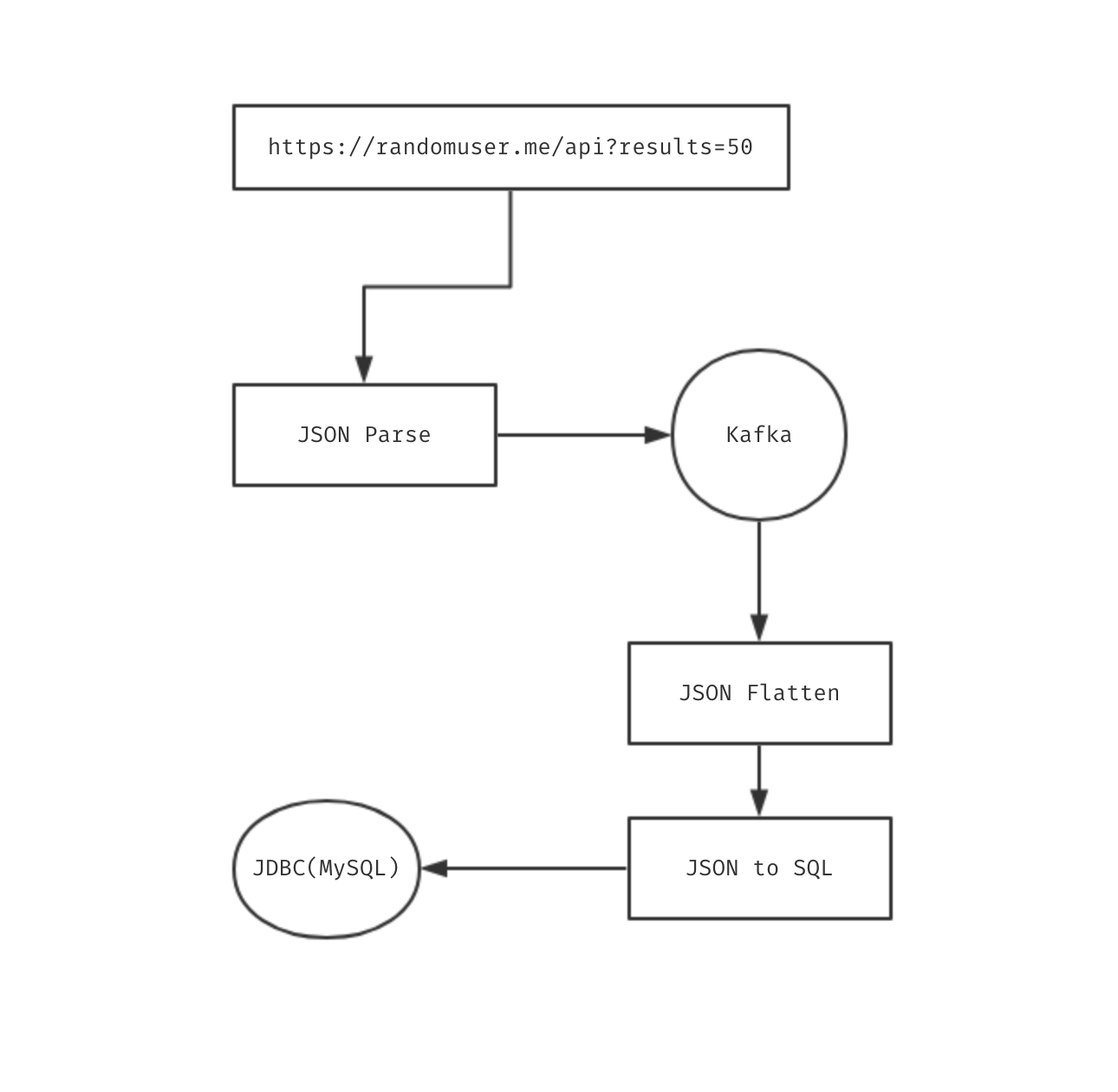
我们需要定义以下数据流,从数据的生产到消费,主要有以下步骤
生产
- 通过 randomuser api 获取用户数据
- 处理返回的数据
- 将处理过后的数据发送给 kafka
消费
- 从 kafka 获取用户数据
- 展开 json 数据
{"login": {"username": "anyisalin"}} -> {"login.username": "anyisalin"} - 将展开后的 json 数据转化为 SQL 语句
- 执行 SQL
StreamSets DataCollector
安装
SDC 的安装包很大,全组件的二进制 6G 左右,安装好 JDK 之后,直接启动即可
streamsets-datacollector-3.6.1/bin/streamsets dc |
默认端口是 18630,用户名密码为 admin/admin
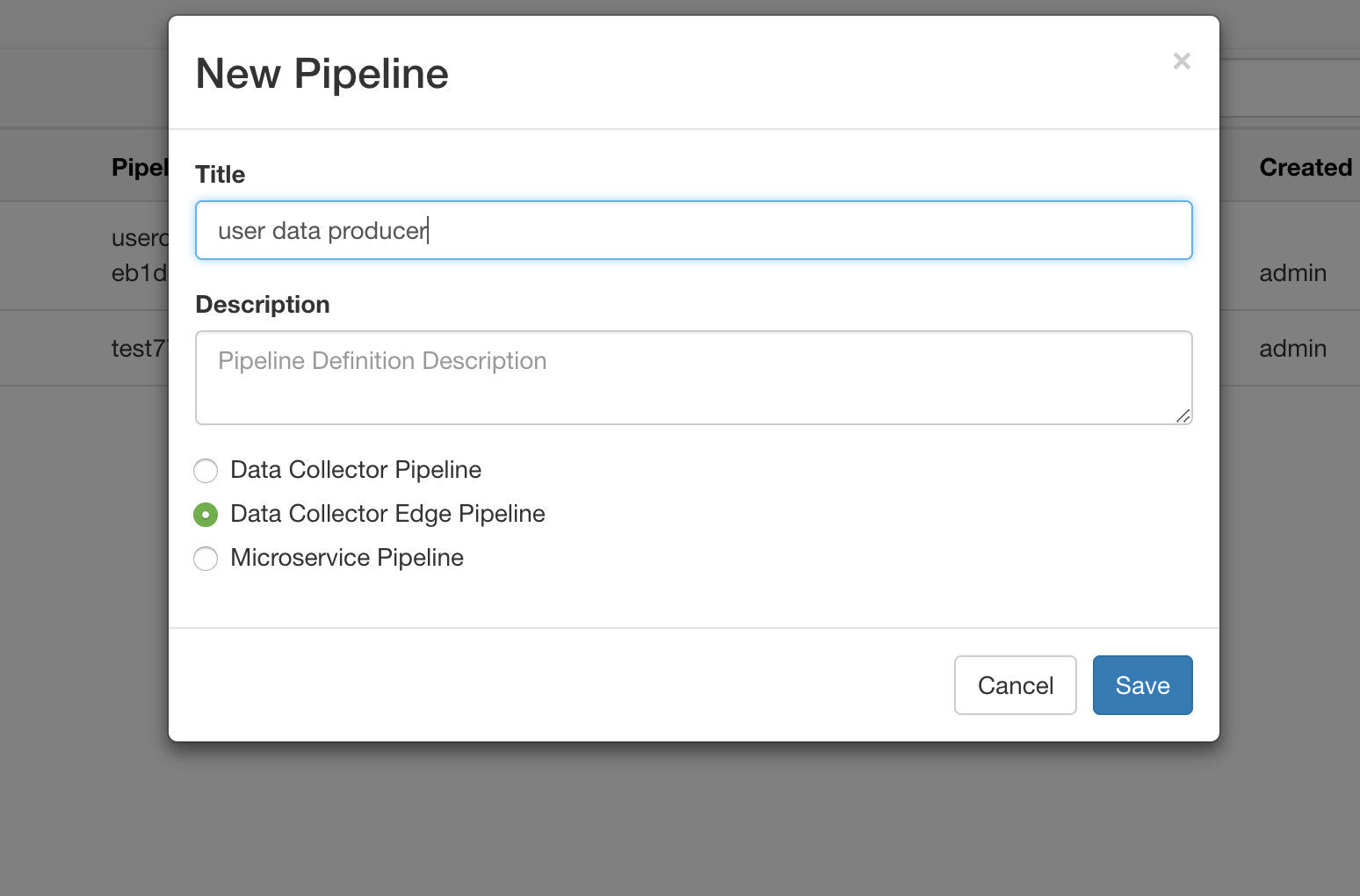
创建 Producer Pipeline
我们创建一个名为 user data producer 的数据流,用来生产用户数据
HTTP Client
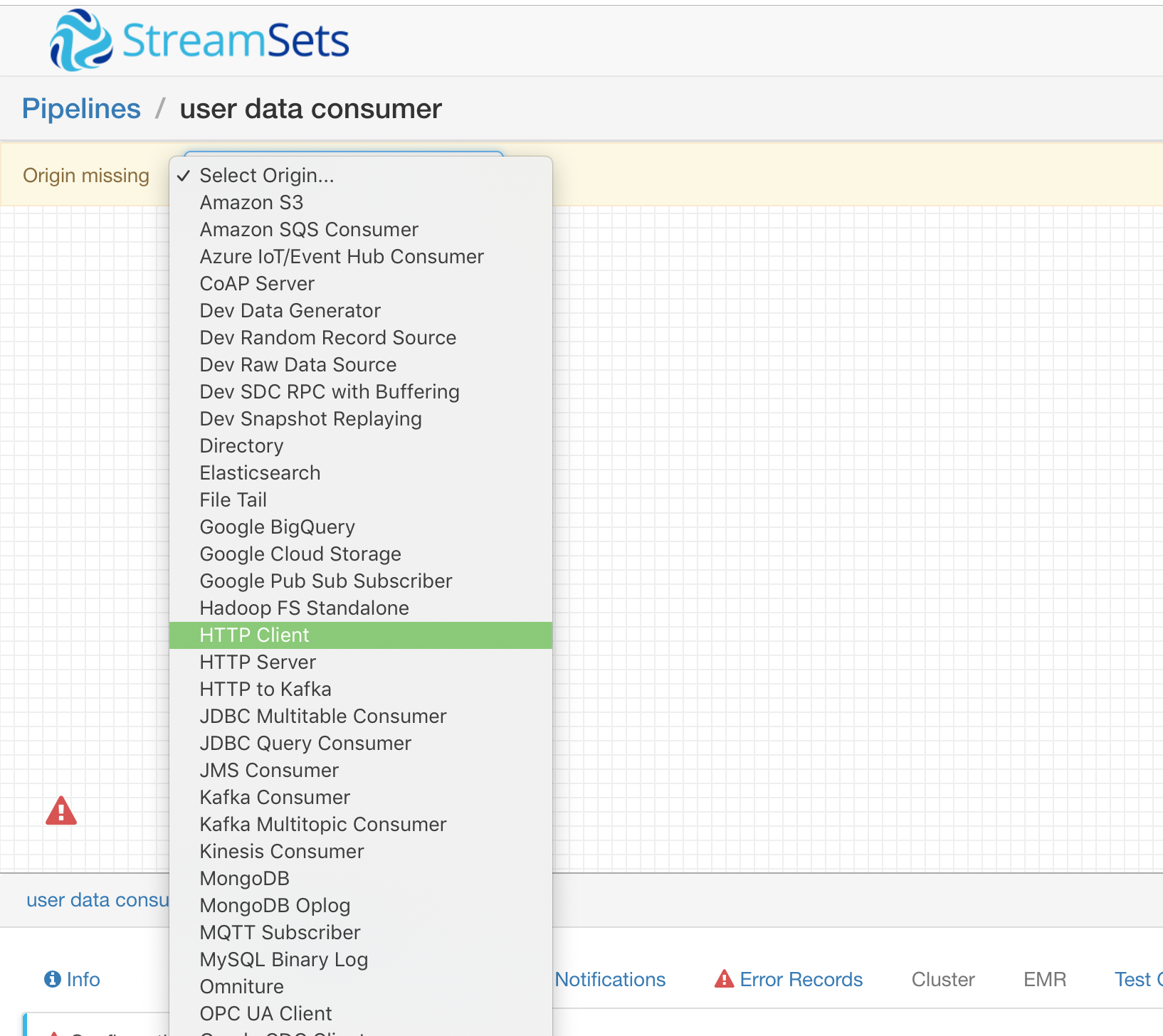
进入 Pipeline 后我们选择一个 Origin (一个 Pipeline 中只能有一个 Origin)
我们需要发起 HTTP 请求来获取数据,所以这里选择 HTTP Client 即可
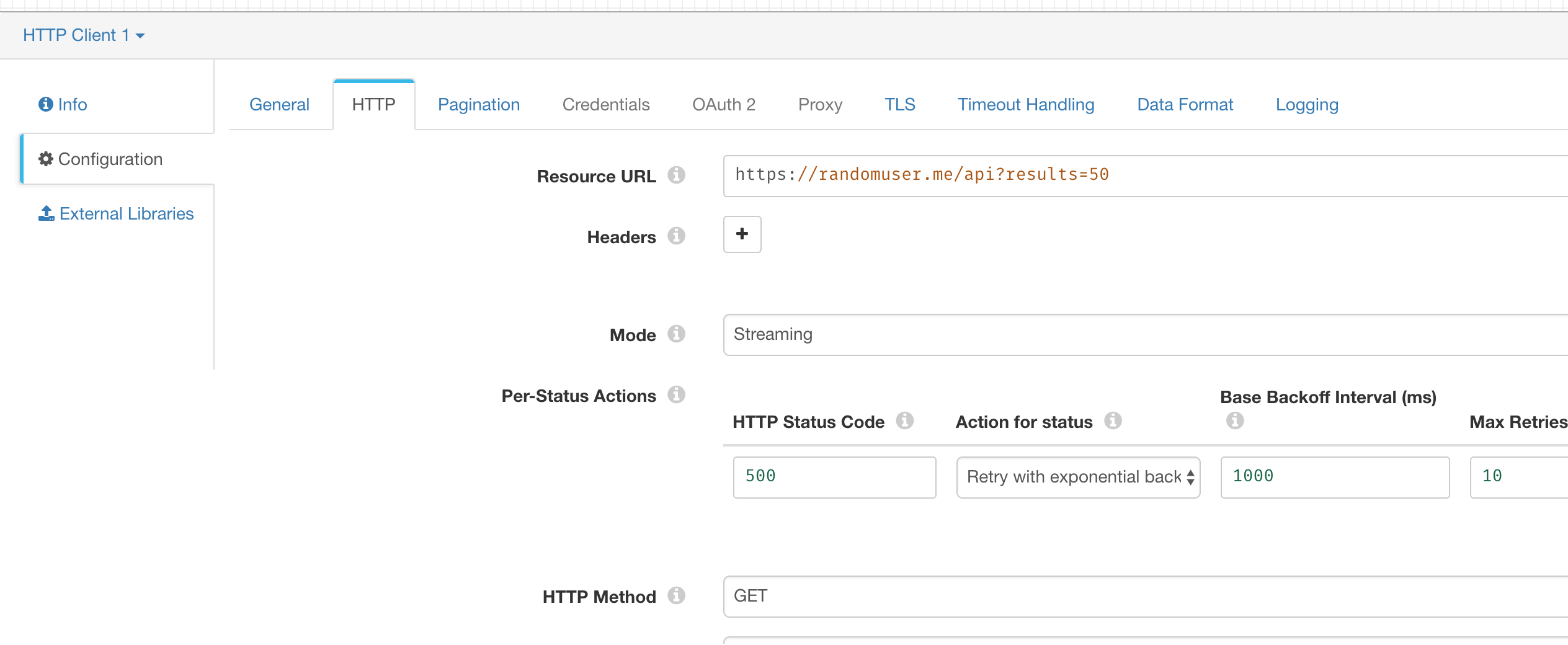
然后配置 HTTP 请求的地址和参数即可
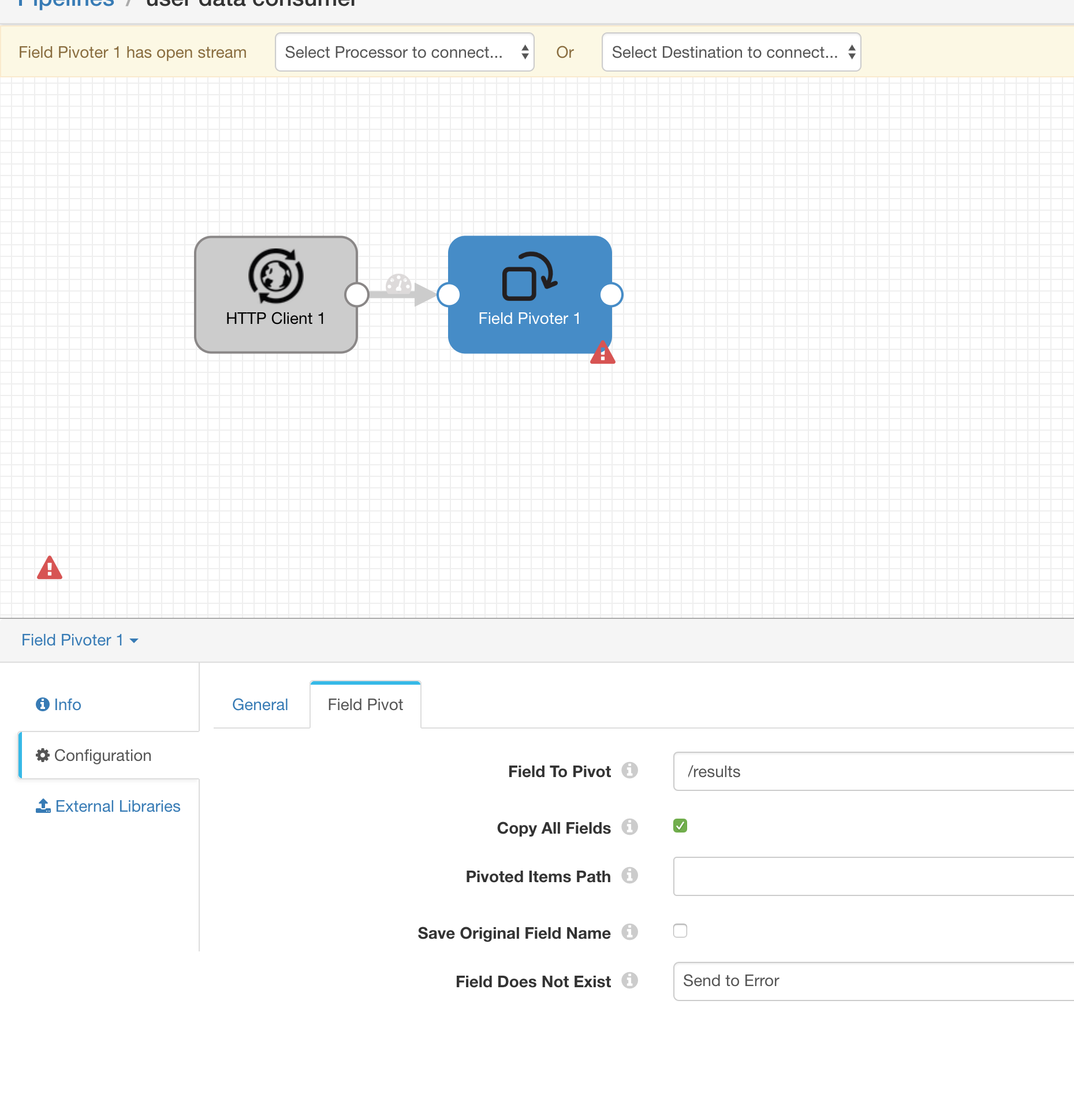
Field Pivoter
由于获取的数据格式如下
{ |
我们只需要里面的 results,所以需要对 JSON 数据进行切分
StreamSets Data Collector 中可以通过 Field Pivoter 这个 Processor 对字段进行切分
所以我们创建 Field Pivoter 并配置即可
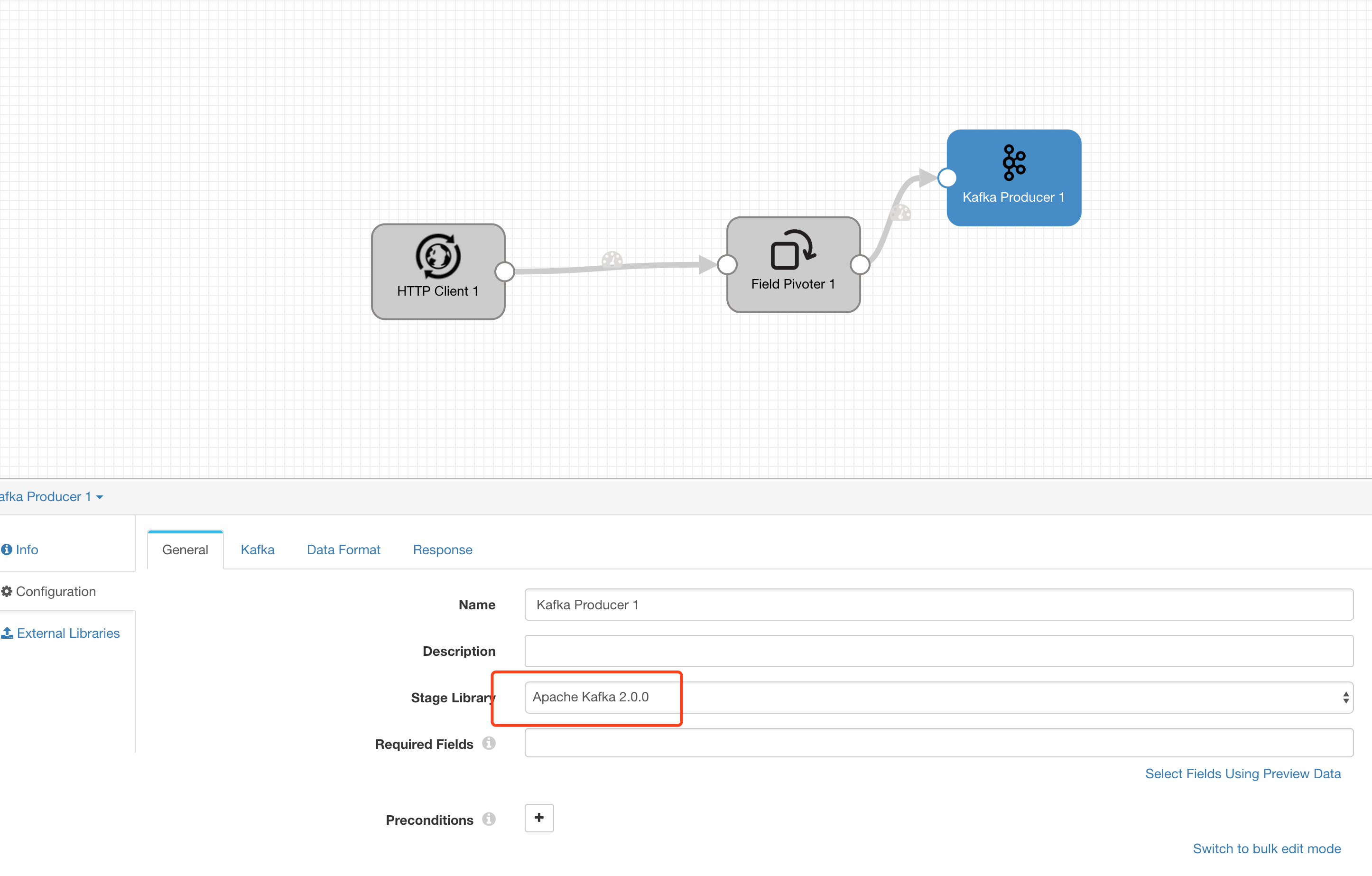
Kafka Producer
最后我们需要将切分后的数据 push 到 kafka 里面
选择 Destination 为 Kafka Producer
选择 Kafka 客户端对应的版本,我们这里使用的是 2.1.1 的 kafka,所以选择 Apache Kafka 2.0.0 这个库
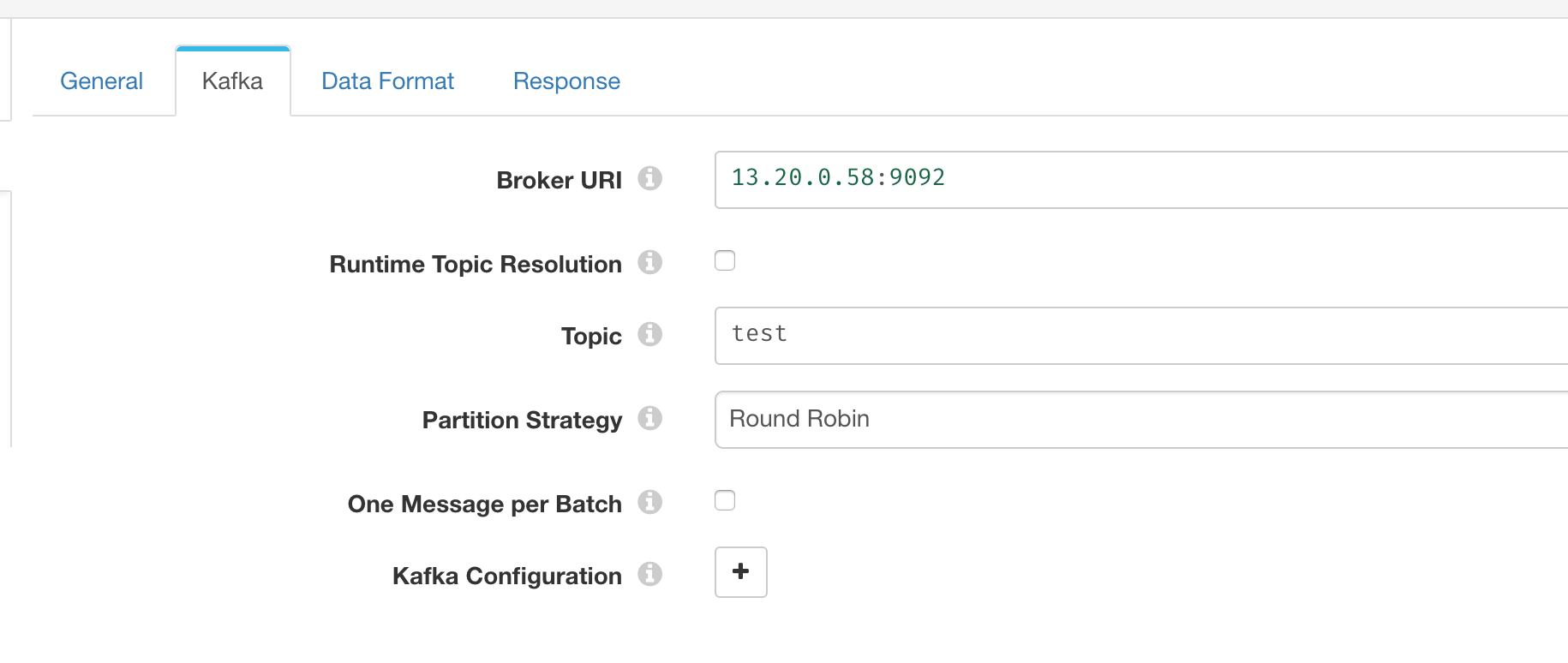
并配置 Kafka Broker 参数
Producer 测试
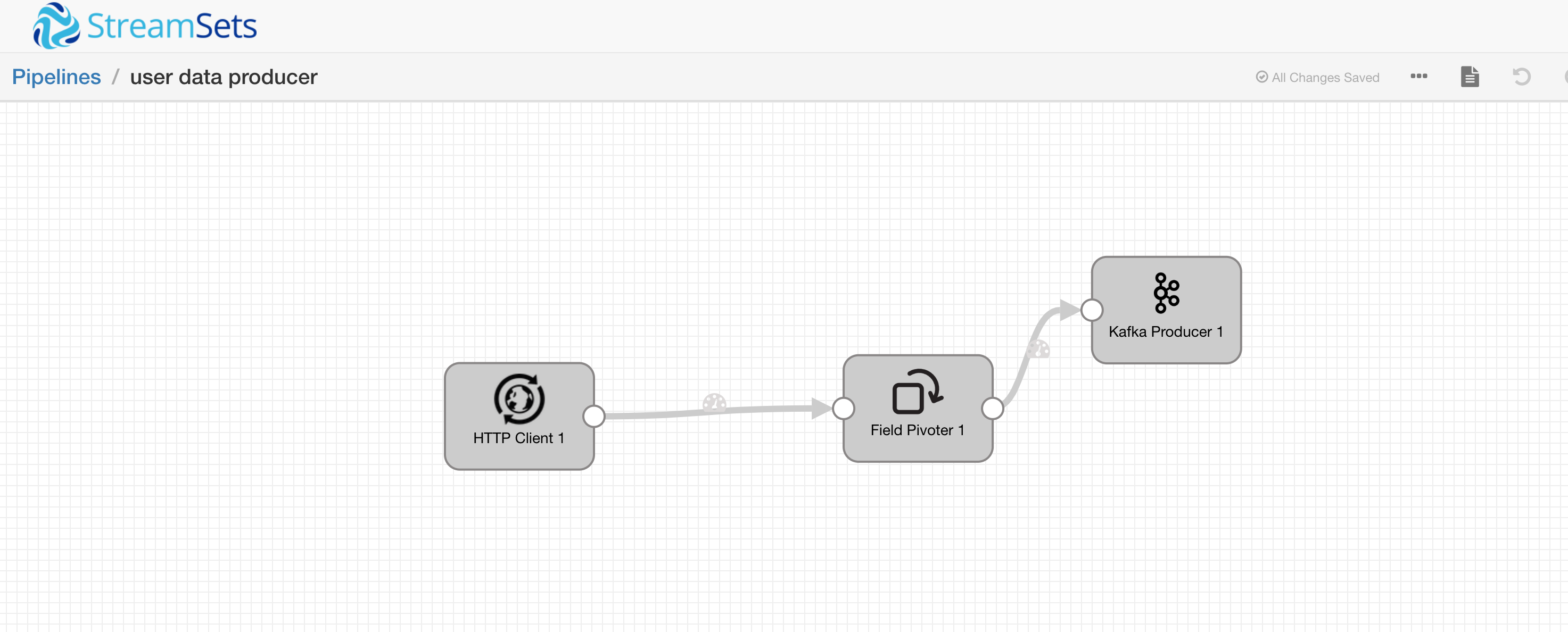
最后我们的 Pipeline 如下
启动并验证
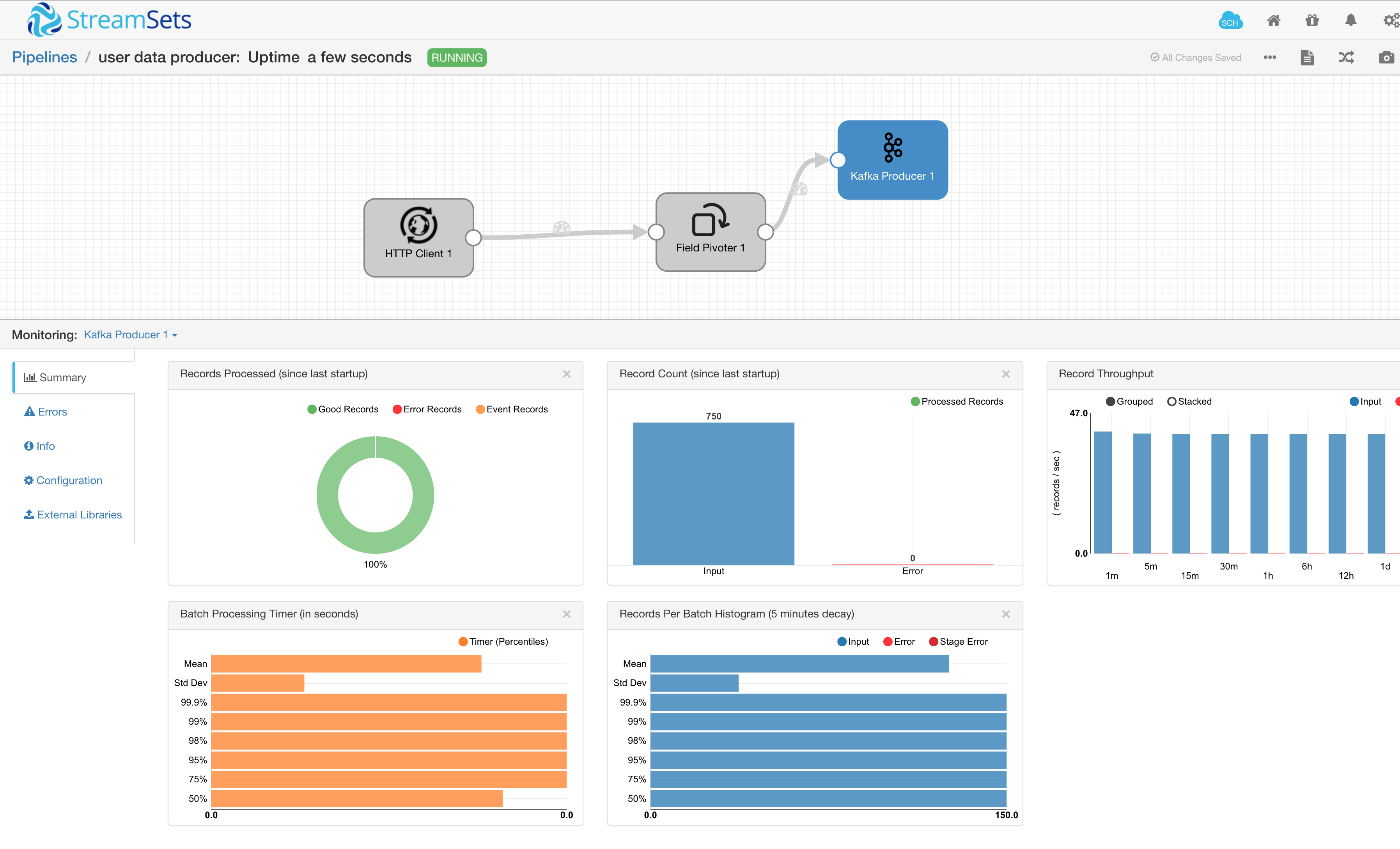
运行 Pipeline 之后,可以看到自带的监控,对记录的统计和汇总
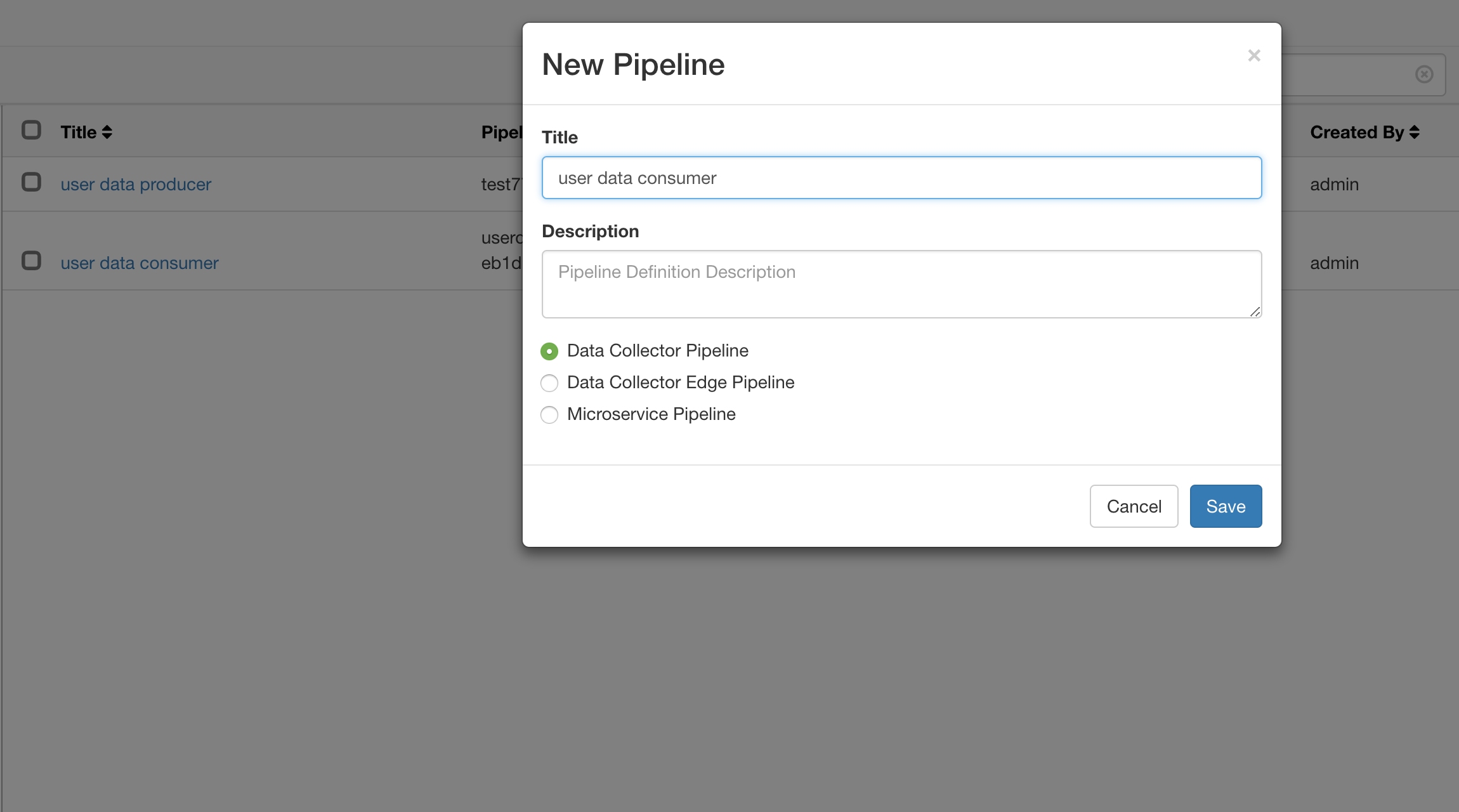
创建 Consumer Pipeline
我们创建一个名为 user data consumer 的数据流,用来消费刚刚生产的数据
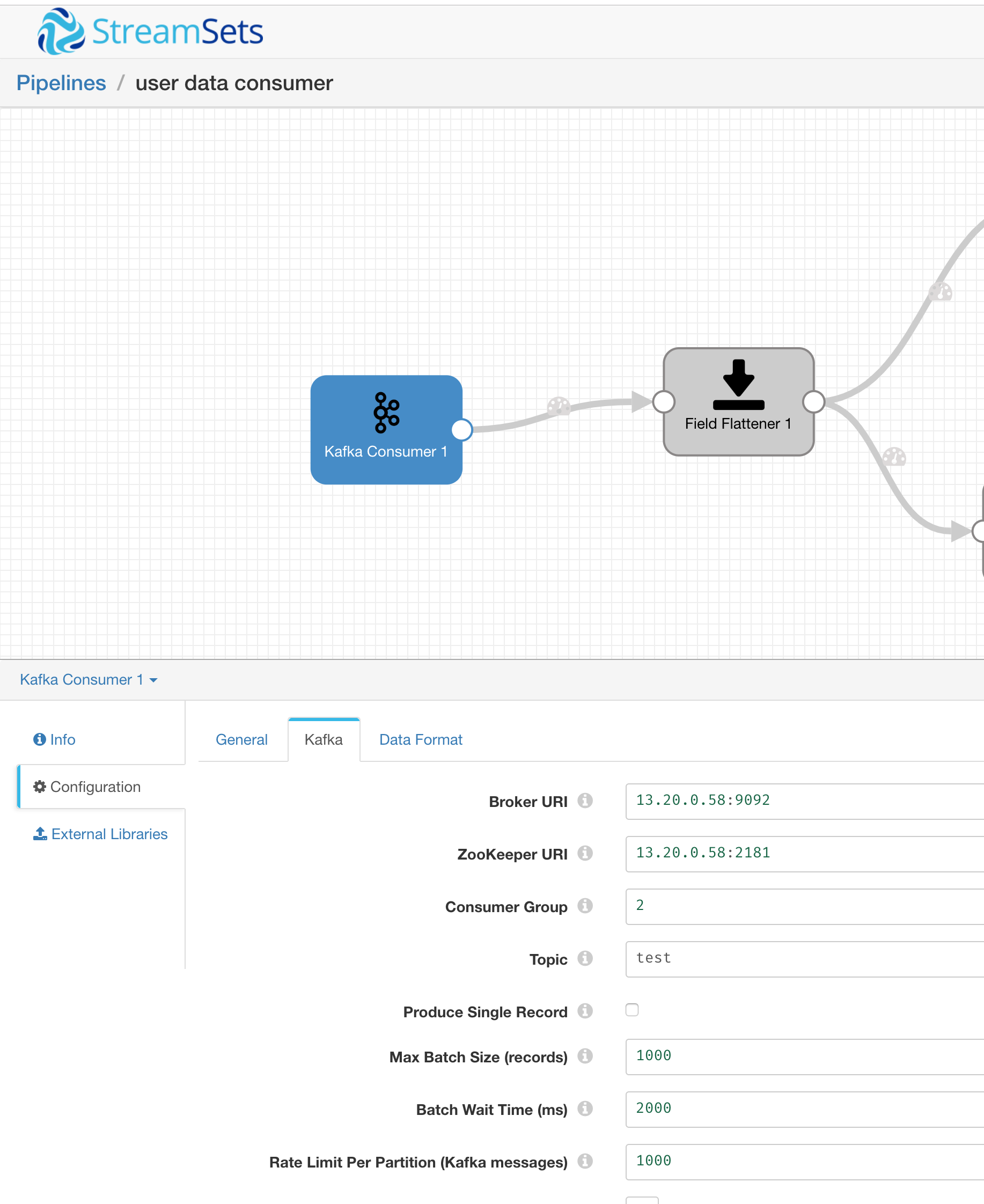
Kafka Consumer
选择 Kafka Consumer 作为 Origin
配置 Kafka Broker 参数
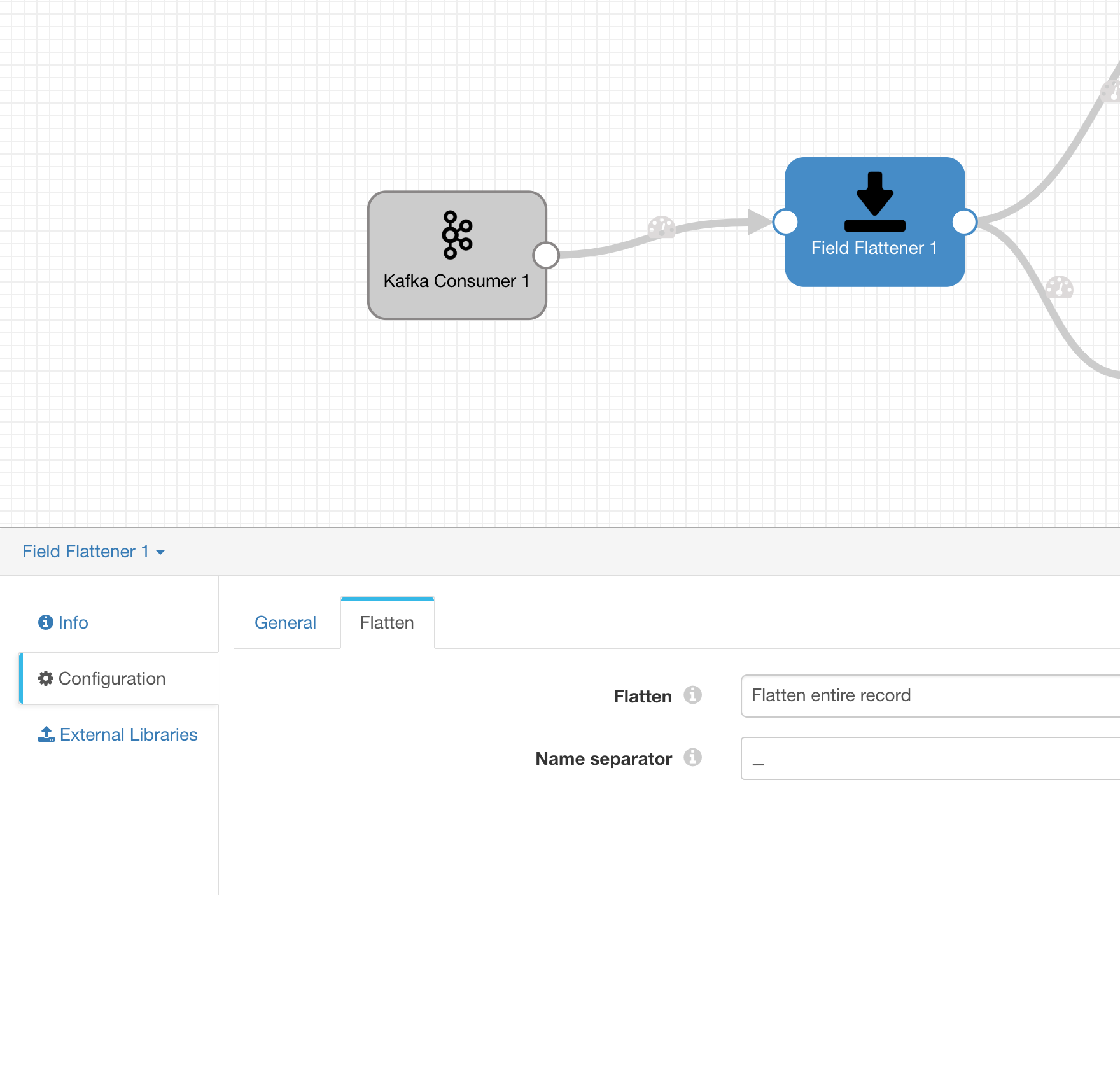
Filed Flattener
我们需要展开 Kafka 中获取到的用户数据
展开的格式如下
{'gender': 'male', |
配置 Field Flattener,分隔符为 _
JDBC Producer
最后我们要将数据插入到 MySQL 里,SDC 通过类型为 JDBC Producer 的 Destination 来处理 SQL 的转换和执行
需要上传对应的库到 SDC 中
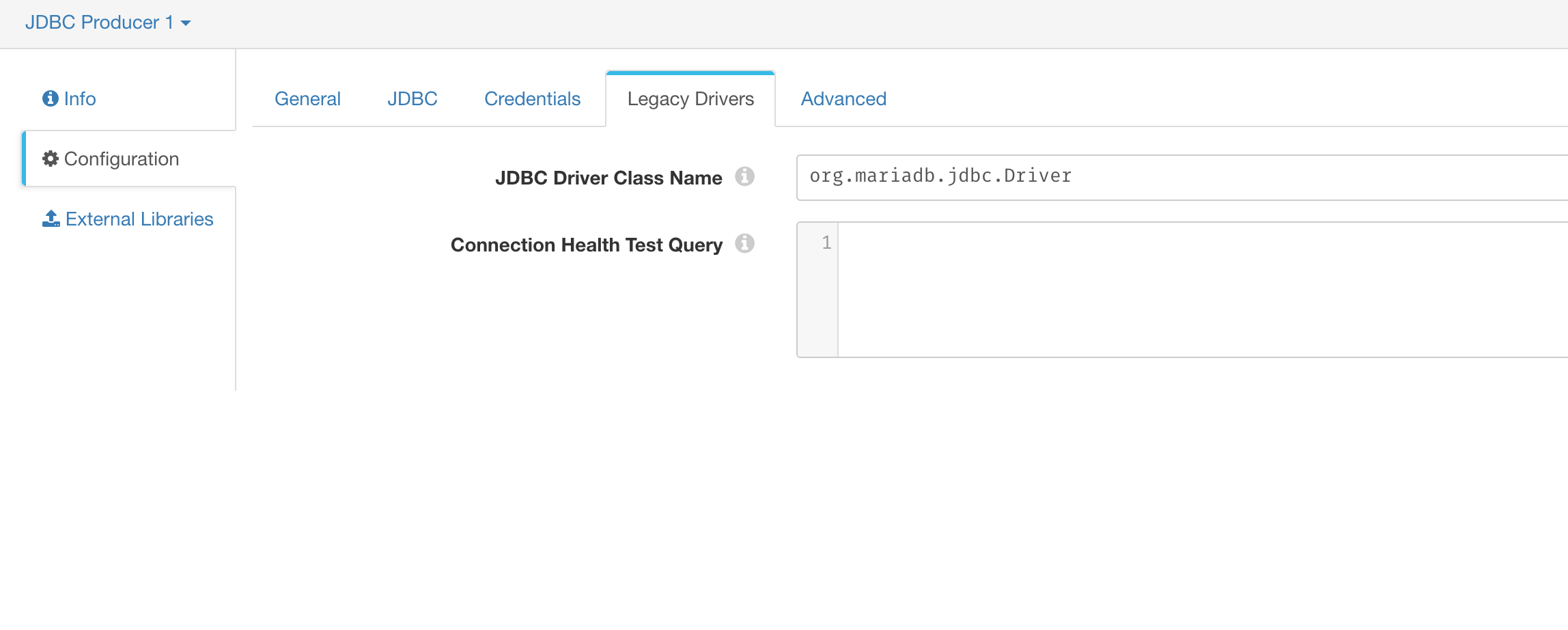
在 Legacy Drivers 里面配置 class
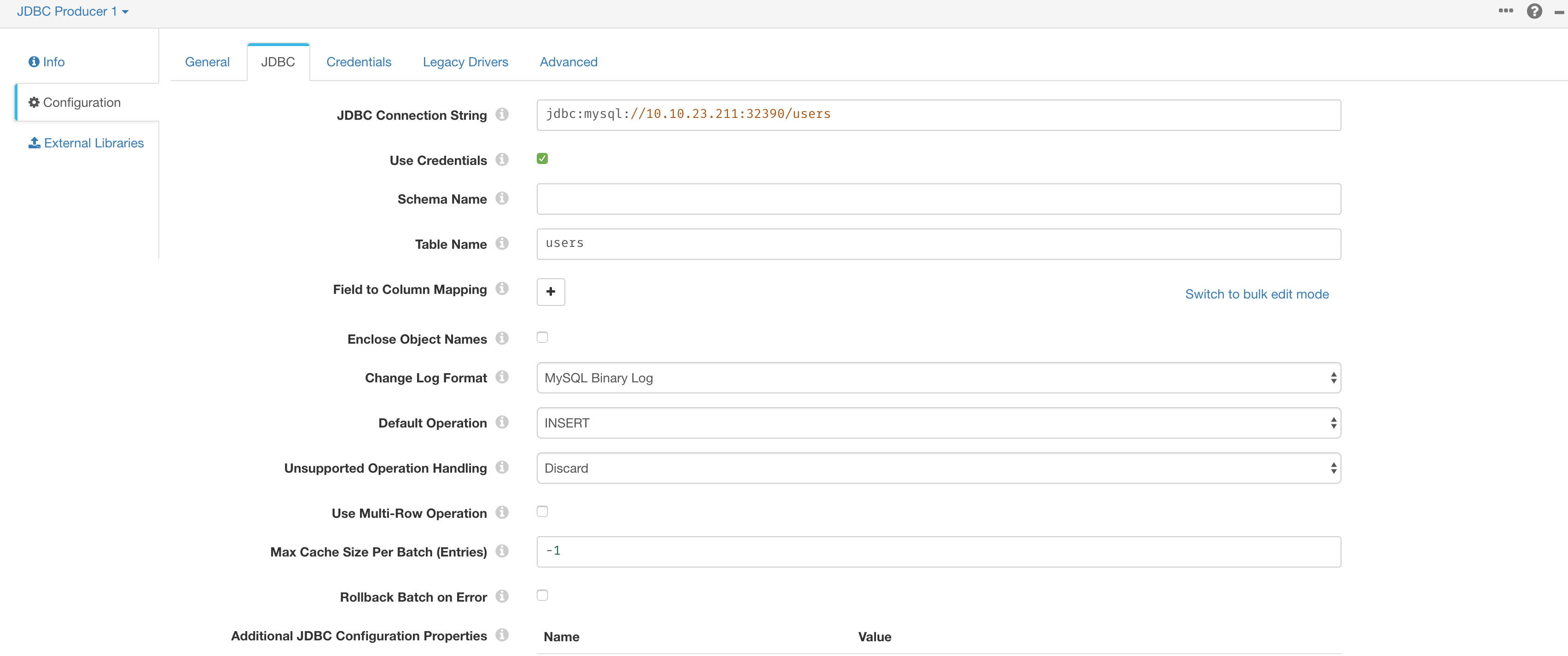
在 Credentials 中配置用户名密码,最后在 JDBC 选项栏中配置连接参数和操作选项
Producer 测试
最后我们启动这个 Pipeline 进行测试
登录 mysql 服务器,查看是否有数据插入
select count(*) from users; |
总结
SDC 定义数据流没有 NiFi 那么灵活,缺少限流,但是界面风格相对 NiFi 好一些,监控图表也很直观